
はじめに
Weighs & Biases(WandB)は機械学習の開発プロセスを支援するためのMLOpsプラットフォームです。本イベントはWandB主催のMLOps関連のMeetupの13回目ということで、Stability AIの渋井氏のモデルサービングの最新手法と、WandBの山本氏によるHeron VLMリーダーボードの紹介、およびチューリングの山口氏による自動運転におけるVLMのデプロイについて非常に濃いお話がありました。
概要
- MLOpsエンジニアの澁井雄介氏(stability aiの中の人)。最近のMLOpsのトレンドについて。
- Weights & Biasesの山本祐也氏。Heron VLM リーダーボードの紹介(チューリングが開発したHeron-Benchを元に最近のVLMを比較できるサイト)。 vlm.nejumi.ai
- チューリング山口祐氏。日本語VLM学習と評価ベンチマークの構築。 の3本立てでした。
「デプロイして本番システムで使うことから考えるAI」 澁井 雄介さん
澁井 雄介さん
 Stability AIでリスクエンジニアやっております。渋井と申します。よろしくお願いします。
今日はデプロイしてから本番でも使うことを考えようっていう話をしていきたいと思います。
Stability AIでリスクエンジニアやっております。渋井と申します。よろしくお願いします。
今日はデプロイしてから本番でも使うことを考えようっていう話をしていきたいと思います。
 自己紹介です。今Stability AI社で機械学習関連とは異なりますが、データ集めや、システム構築のような仕事をしています。最近作ってるものとして、Stable Artisanという生成AIで画像生成とかDiscodeなどで使えるものを作っているので、もし興味があれば使っていただけると幸いです。今回の資料についてはスピーカーデックにあげています。今日の話は私個人の見解で、所属している会社を代表するものではないことをお断りしておきます。
自己紹介です。今Stability AI社で機械学習関連とは異なりますが、データ集めや、システム構築のような仕事をしています。最近作ってるものとして、Stable Artisanという生成AIで画像生成とかDiscodeなどで使えるものを作っているので、もし興味があれば使っていただけると幸いです。今回の資料についてはスピーカーデックにあげています。今日の話は私個人の見解で、所属している会社を代表するものではないことをお断りしておきます。
 個人の宣伝ですが、本を2冊出していて、機械学習を実用化するためのシステムの作り方とか、実際にシステム作っていくうえで、ソースコードを全部書いてるような本を出しています。
個人の宣伝ですが、本を2冊出していて、機械学習を実用化するためのシステムの作り方とか、実際にシステム作っていくうえで、ソースコードを全部書いてるような本を出しています。
 先月5月まで10ヶ月くらいMLOpsについてSoftware&Designで書いてます。この連載も興味あったらよろしくお願いします。ということで、本題に入っていきます。
先月5月まで10ヶ月くらいMLOpsについてSoftware&Designで書いてます。この連載も興味あったらよろしくお願いします。ということで、本題に入っていきます。
 機械学習のシステムを作るうえで、学習の部分については、いろんな本とか、テックブログとかで、ファイルを使ったり、検索を使ったりということはサンプルコードを含めてあるとは思います。
これだけ世界で色々使われるようになって、そのシステムっていうのは同じような課題もあると思います。
機械学習のシステムを作るうえで、学習の部分については、いろんな本とか、テックブログとかで、ファイルを使ったり、検索を使ったりということはサンプルコードを含めてあるとは思います。
これだけ世界で色々使われるようになって、そのシステムっていうのは同じような課題もあると思います。
それをプロダクションの中に出していく、機械学習の技術の中で価値を生み出していくところで、難しさもあります。 Googleが機械学習のシステムを作るにあたって隠れた負債について論文を7年くらい前に出していて、これで機械学習以外のところも頑張って作らなければいけないということを話したりしています。
それが生成AIの世界になってきて、7年前の当時に生成AIこんなに流行るか多分誰も予想してなかったと思います。
 生成AIに入る前にもうちょっと一般的にAIを本番システムで使うという話から始めていきたいのですが、
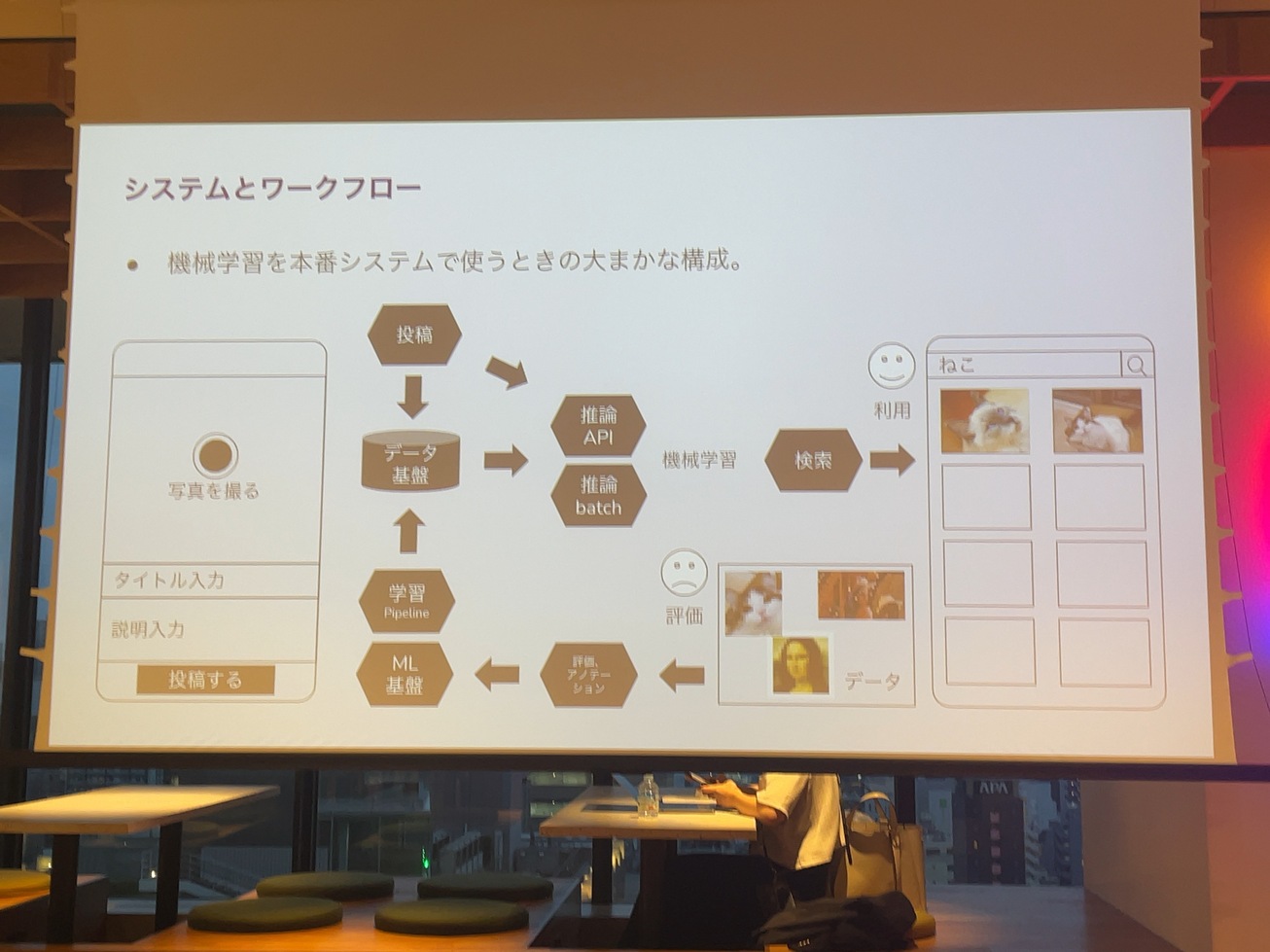
一番わかりやすい例としては、コンテンツ投稿系のアプリ、XとかInstagram、Facebook、YouTubeといったいろんなコンテンツを扱うアプリがあると思いますが、そのアプリの投稿するところから検索できるようにするところまでの間のどこかに機械学習を組み込んで、ユーザーの体験を改善したり、悪いことしてる人がいないかを探すみたいなところで使うというのは、機械学習のごく一般的な使い方だと思います。
生成AIに入る前にもうちょっと一般的にAIを本番システムで使うという話から始めていきたいのですが、
一番わかりやすい例としては、コンテンツ投稿系のアプリ、XとかInstagram、Facebook、YouTubeといったいろんなコンテンツを扱うアプリがあると思いますが、そのアプリの投稿するところから検索できるようにするところまでの間のどこかに機械学習を組み込んで、ユーザーの体験を改善したり、悪いことしてる人がいないかを探すみたいなところで使うというのは、機械学習のごく一般的な使い方だと思います。
ユーザーがスマホの画面で投稿ボタンを押したら、バックエンドの投稿APIでデータベースや、データ基盤からデータが入り、推論のAPIだとか、レコメンデーションのAPIを通して、検索システムの方でユーザーが新しい猫ちゃんや、かわいい猫ちゃんを探しやすいようにする。さらに検索システムの中での駆動状況を見ながら、より良い機械学習を作っていくのは、MLOpsと呼ばれるものの一般的なやり方だと思っています。
実際にそういったものを作るのは、あくまで投資であって、ビジネスが必要で、そのためにこんなものを作らなきゃいけないと言う人が必要だと思います。そのためには、ユーザーにこれだけの価値があるっていうことを説明しなきゃいけないので、可能な限りユーザーの価値に近いところから機械学習を使うということを説明していこうと思います。
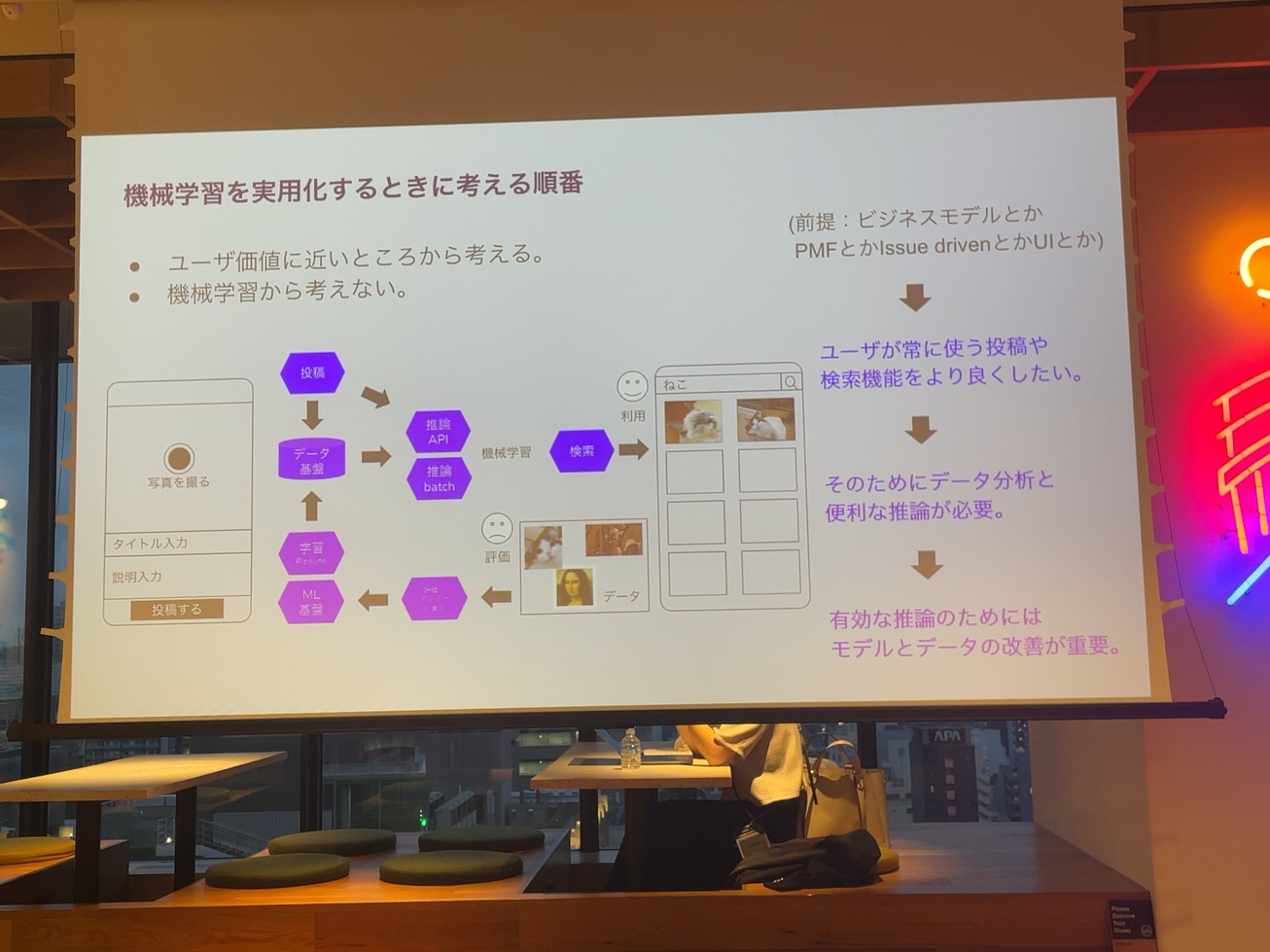 機械学習を使っていく上で、実際にシステムを作ってる人たちがどんなところで困ってるかっていうと。
機械学習を使っていく上で、実際にシステムを作ってる人たちがどんなところで困ってるかっていうと。
私、このスライド作ったのは確か4年か5年ぐらい前で。未だに発生している過程だからなんですけど、機械学習に使った開発環境と、推論環境というのがあまりにも違いすぎて学習したモデルを推論システムに組み込もうとしたら、みんなが苦労するというようなことは、5年前から未だに解決されてない課題だと思っています。その課題っていうのは、開発に当たってPyTorchとかKerasみたいな、いわゆるバッチ処理で使われるライブラリが使われますが、推論にはTorchServeとかTensorFlowサービスとかが使われます。実は学習したモデルがそのまま推論に使われることはほとんどなく、モデルの中に含まれてない学習とか、後処理みたいなものを全部推論のために書き直さなきゃいけないっていうようなところがあります。このような課題が今だに残ってるため、大変さを感じています。 データが正しくないと機械学習のモデルも正しくなくなります。しかもそのデータが正しくないというのが、実は提出した後でわかるということはよくあることだと思っています。例えばデータリークが最初のデータを取得するところで発生してる場合があります。
 学習も評価の部分も全部うまくいったように出てきて、このモデルすげえっていうふうになるんですけど、リリースしてみたら実はリークしていたから使い物にならないっていうようなことは、未だに結構あるものだと思っています。
この手戻りというのは、例えば画像分類くらいのモデルだったら、GPUのコストとかモデルの解析とかも、そこまで大きくないと言えるぐらいだったら、戻してもいいかなって思うかもしれません。
学習も評価の部分も全部うまくいったように出てきて、このモデルすげえっていうふうになるんですけど、リリースしてみたら実はリークしていたから使い物にならないっていうようなことは、未だに結構あるものだと思っています。
この手戻りというのは、例えば画像分類くらいのモデルだったら、GPUのコストとかモデルの解析とかも、そこまで大きくないと言えるぐらいだったら、戻してもいいかなって思うかもしれません。
LLMを学習して作っているシステムだと、例えばNejumiリーダーボードはすごくいい成績だけど、実はリークしてるデータを使ってるから、よく見えてるだけだった。みたいな事例もあるんじゃないかなというのもあります。
 でそういったところを考えていくにあたって、私が機械学習のシステム、もう6年、7年以上ですかね。常にこういうふうにやろうと決めてることが一つあって、推論の部分まで一気に作り切ってから、学習とか全部後回しにして、推論の部分もある程度後で考え直そうみたいなことをやってます。これ、何が言えるのかっていうと、最初にインテグレーションテストができるっていうところです。
でそういったところを考えていくにあたって、私が機械学習のシステム、もう6年、7年以上ですかね。常にこういうふうにやろうと決めてることが一つあって、推論の部分まで一気に作り切ってから、学習とか全部後回しにして、推論の部分もある程度後で考え直そうみたいなことをやってます。これ、何が言えるのかっていうと、最初にインテグレーションテストができるっていうところです。
 さっきの画像投稿のコンテンツ自体を作る。その画像を投稿して、その後ろでレコメンデーションとかランキング指標みたいなものが動いていて、そこに対してAPIとしてリフレッシュを送るみたいなことやらなきゃいけないんですけど、外部にリクエストを送って、そのランキングとかレコメンデーションをとってくるっていうところがちゃんと動いてないと、結局、機械学習のモデルがどんなものが動いたとしても意味はないので、先にインテグレーションをして、インテグレーションテストを書く。その後でモデルの方もさらに良くしていくっていうような流れで、その場合ってすごくいいモデルじゃないけど、最悪そのようなモデルでも一応リリースすることはできる。システムは出来上がっているのであとは機械学習の一番楽しいモデルを学習するっていう、美味しいものは後まで残しておくっていうような考えです。
さっきの画像投稿のコンテンツ自体を作る。その画像を投稿して、その後ろでレコメンデーションとかランキング指標みたいなものが動いていて、そこに対してAPIとしてリフレッシュを送るみたいなことやらなきゃいけないんですけど、外部にリクエストを送って、そのランキングとかレコメンデーションをとってくるっていうところがちゃんと動いてないと、結局、機械学習のモデルがどんなものが動いたとしても意味はないので、先にインテグレーションをして、インテグレーションテストを書く。その後でモデルの方もさらに良くしていくっていうような流れで、その場合ってすごくいいモデルじゃないけど、最悪そのようなモデルでも一応リリースすることはできる。システムは出来上がっているのであとは機械学習の一番楽しいモデルを学習するっていう、美味しいものは後まで残しておくっていうような考えです。
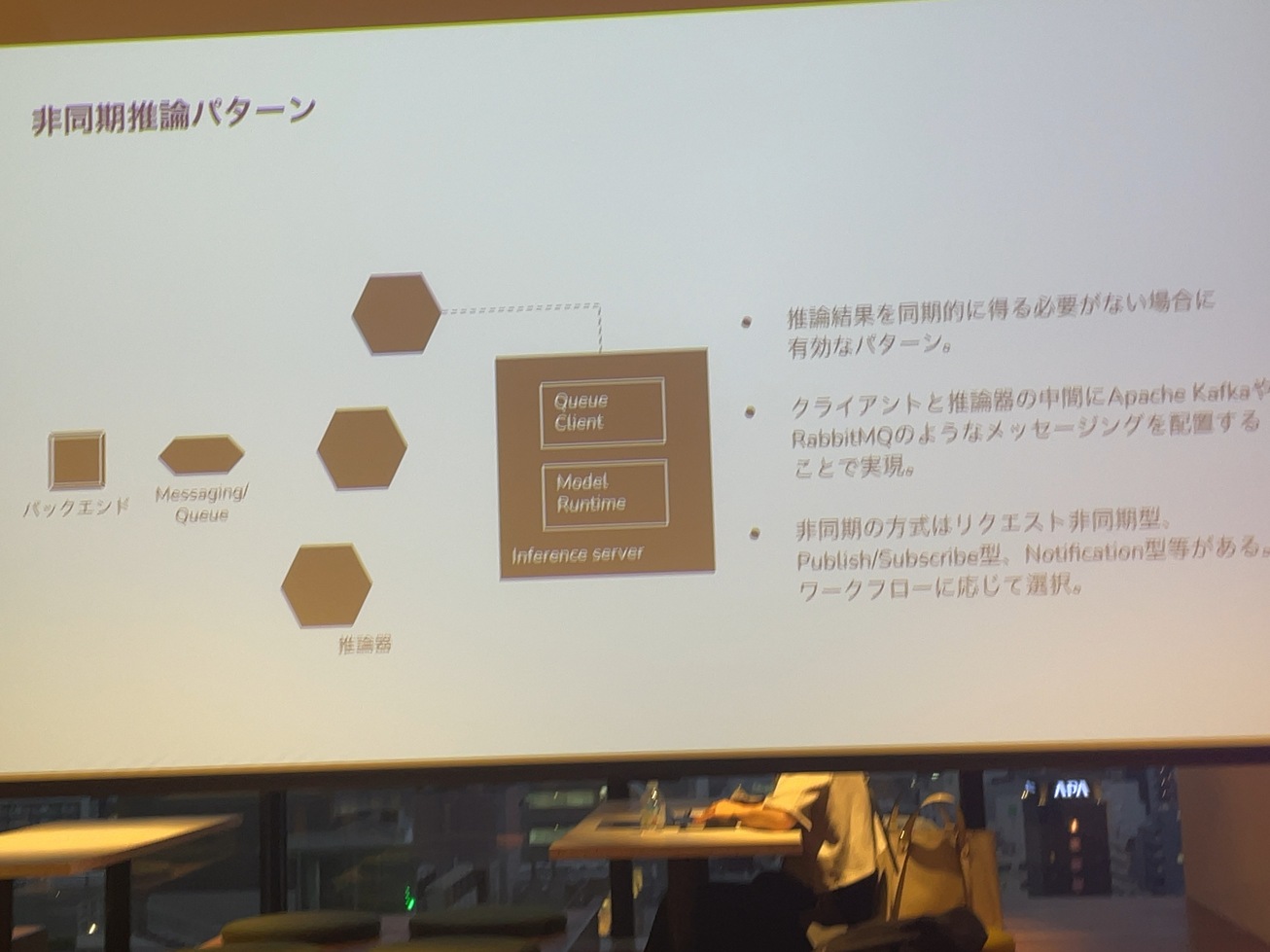
 で機械学習を実用化する時に、やり方としては、例えばREST APIを作って同期的に推論するっていうのもあるし、バックエンドと推論器の間に、RabbitMQとかApache Kafkaみたいなものを置いて非同期にするっていうようなやり方もあると思います。
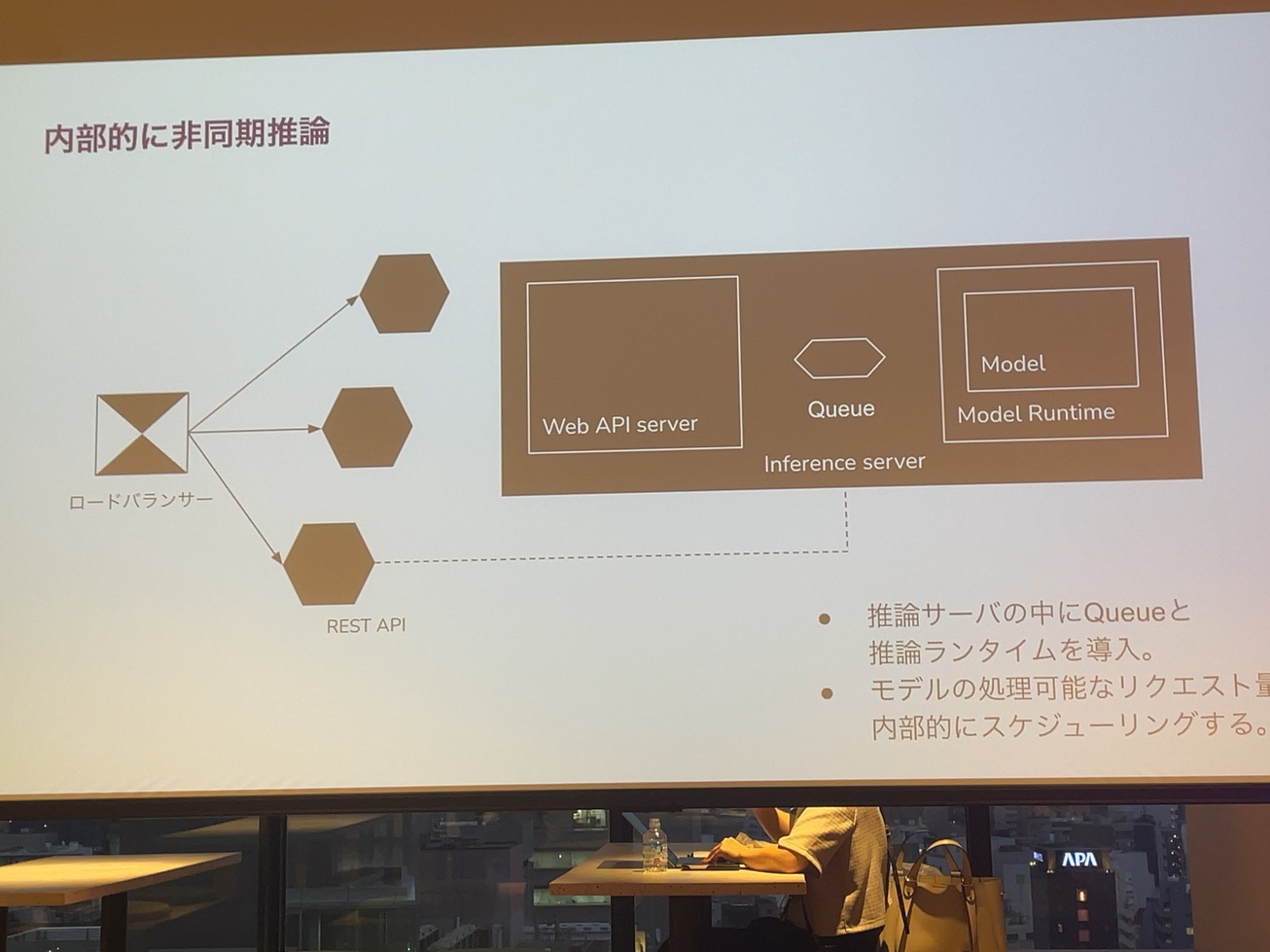
で、最近のLLMの推論システムとかのソースコード見てると、Inference Serverの中にWebのAPIサーバーを用意しておいて、そこと推論のランタイムとキューっていうことをよくやってたりします。これってそもそもLLMの推論って一回が重いっていうのがあって、かつ考えているバッチは止めて処理したいっていうのがあるので、キューの部分でスケジューリングし直して一気に推論の部分をバッチリまとめるっていうような手段らしいです。この後詳しく話します。
で機械学習を実用化する時に、やり方としては、例えばREST APIを作って同期的に推論するっていうのもあるし、バックエンドと推論器の間に、RabbitMQとかApache Kafkaみたいなものを置いて非同期にするっていうようなやり方もあると思います。
で、最近のLLMの推論システムとかのソースコード見てると、Inference Serverの中にWebのAPIサーバーを用意しておいて、そこと推論のランタイムとキューっていうことをよくやってたりします。これってそもそもLLMの推論って一回が重いっていうのがあって、かつ考えているバッチは止めて処理したいっていうのがあるので、キューの部分でスケジューリングし直して一気に推論の部分をバッチリまとめるっていうような手段らしいです。この後詳しく話します。
GPUを推論に使ってテキスト処理が爆上がりしてるってなったら、それを維持することができなくなるってこともあり得る話なので最初のうちに、そういったシステムを作っておいて、本当にこのシステム出して大丈夫なのかっていうのを確認できる状態を作るっていうのはすごい重要な開発のやり方だと私は最近は思っております。
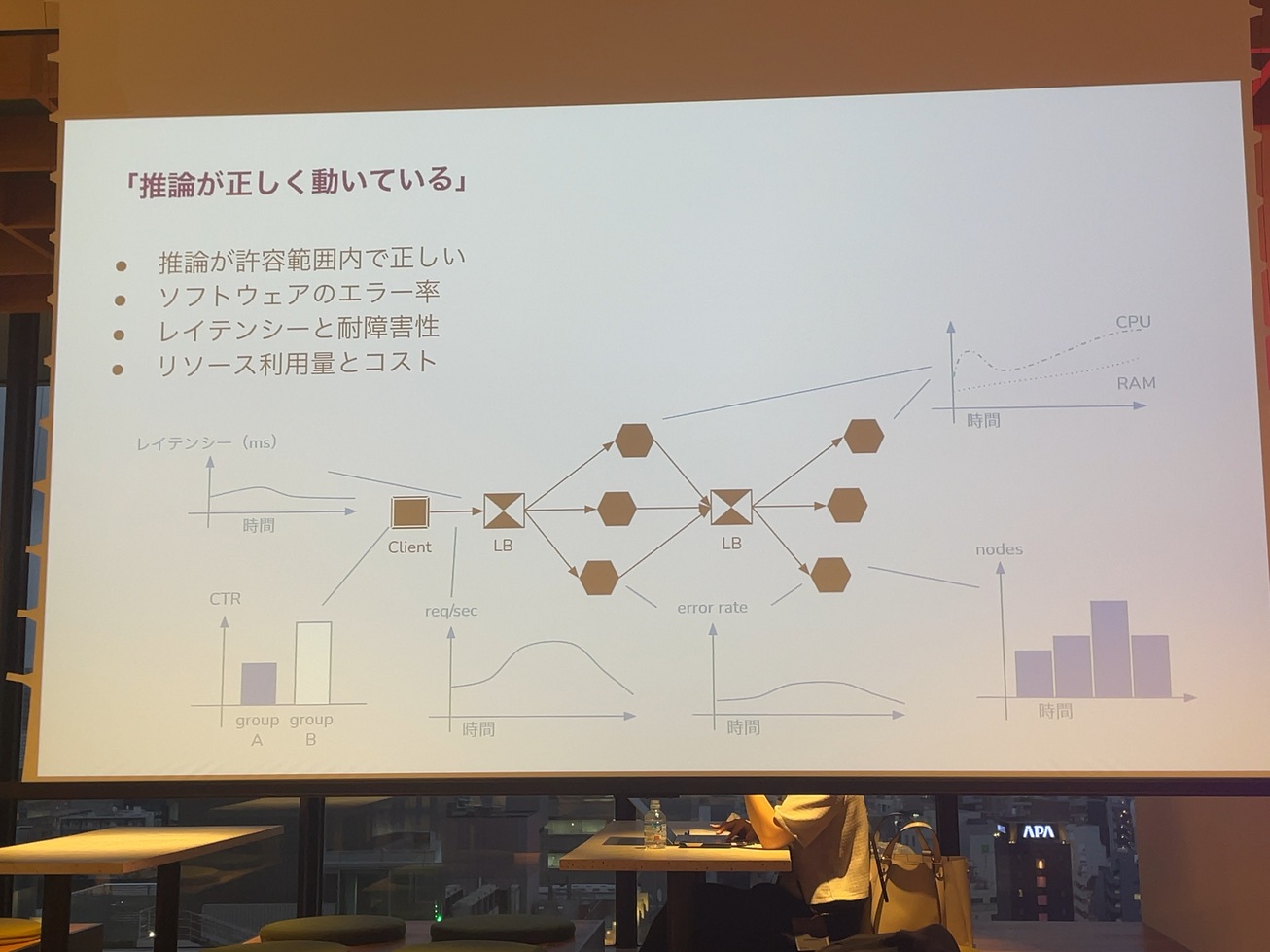 機械学習のシステム。推論システムっていうのを作っていくいろんなパターンがあります。受け入れるものを最初に書いちゃった方がいいですよっていう話をしたんですけど、
この辺って推論システムがちゃんと動いているっていうのを本来世の中にサービス提供する時って、そのシステムがちゃんと動いててそれがテスト可能であったり、使うことが可能っていう条件のもとに、本当に役に立ってるのかっていうのを仮説検証できるシステムを作っています。
出せないものを作っても意味がないので、ちゃんと出しましょうと。その作ったものが本当にちゃんと動いてるのかっていうのは、いろんなメトリックスだとか、ログを取って検証します。
例えば、推論の結果っていうのが明らかに問題ないっていうこともあれば、ソフトウェアのエラー率であるとか、レイテンシーを見ます。
機械学習のシステム。推論システムっていうのを作っていくいろんなパターンがあります。受け入れるものを最初に書いちゃった方がいいですよっていう話をしたんですけど、
この辺って推論システムがちゃんと動いているっていうのを本来世の中にサービス提供する時って、そのシステムがちゃんと動いててそれがテスト可能であったり、使うことが可能っていう条件のもとに、本当に役に立ってるのかっていうのを仮説検証できるシステムを作っています。
出せないものを作っても意味がないので、ちゃんと出しましょうと。その作ったものが本当にちゃんと動いてるのかっていうのは、いろんなメトリックスだとか、ログを取って検証します。
例えば、推論の結果っていうのが明らかに問題ないっていうこともあれば、ソフトウェアのエラー率であるとか、レイテンシーを見ます。
 あと最後によくやるよくあるというか。私は未だに苦しむのが、
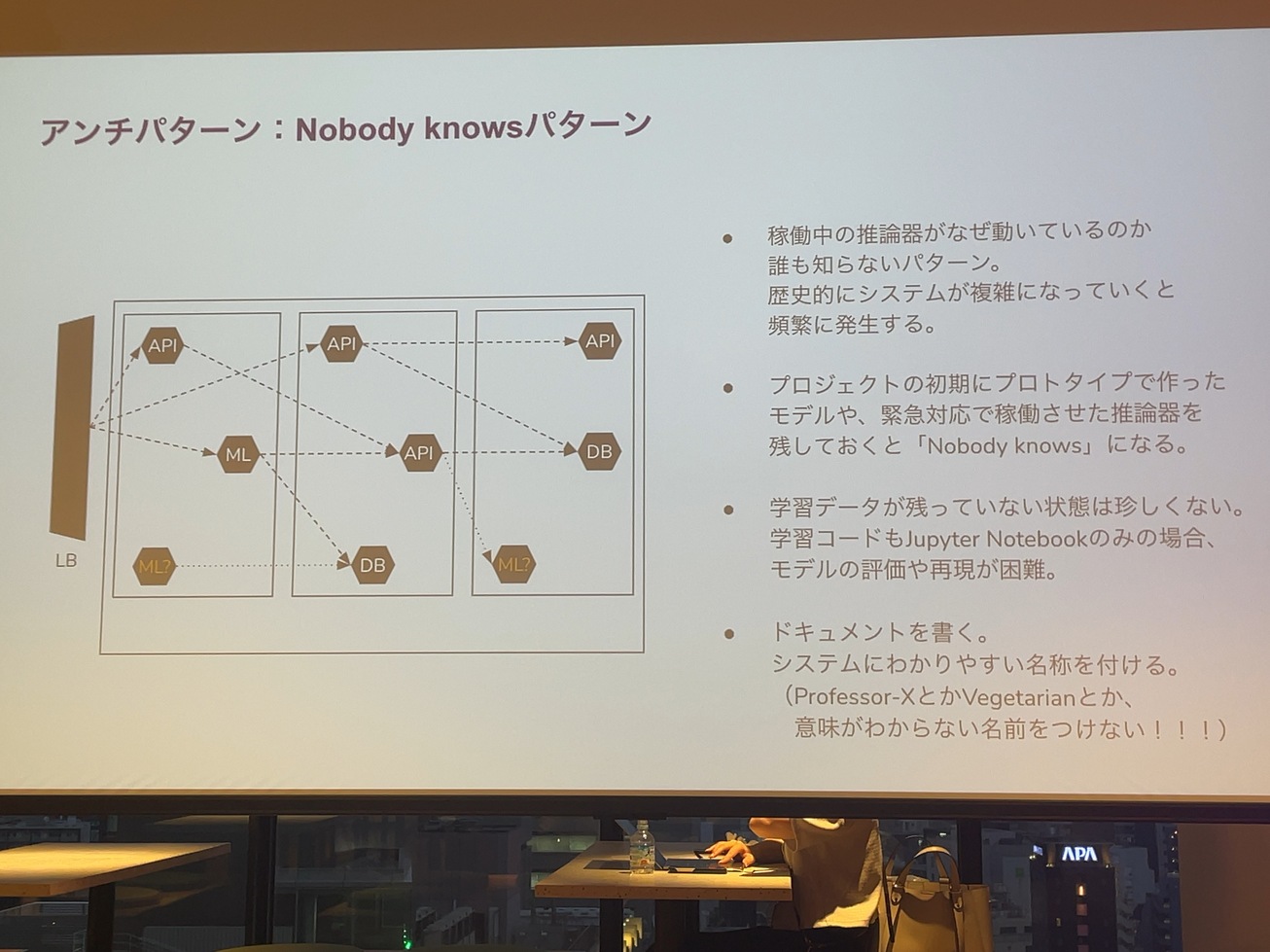
システムのアンチパターンとして、誰かが作ったよくわからないエムエルのシステムとか、推論器が動いてて、誰も知らないし、普通に作った人辞めちゃったっていうので消していいのかよくわからないものっていうのが残っているというのもあると思います。
あと最後によくやるよくあるというか。私は未だに苦しむのが、
システムのアンチパターンとして、誰かが作ったよくわからないエムエルのシステムとか、推論器が動いてて、誰も知らないし、普通に作った人辞めちゃったっていうので消していいのかよくわからないものっていうのが残っているというのもあると思います。
本当に初期のプロトタイプで作ったものであるとか、緊急対応で推論器を作んなきゃいけなかったっていうパターンって、ビジネスやっていれば、いくらでもあるとは思うんですけど、 ドキュメントが残ってなかったり、作った人がいなかったり、もしくはAPIからなんかモデルが動いてるけど、そのモデルの中身を見るのって基本的に無理な人が多いし、 学習データが残ってないってことも、すごい苦労するというか、よくあったりします。
で最悪なのが推論した結果っていうのがデータベースに登録されていて、そのデータベースの絡みもどっかのサーバーが見てるっていうような状態で、これって消していいか本当によくわからなくなるっていうのは、 大事な要素になればなるほど意味がありそうなので、これって緊急対応の時にやったものだから必要ないっていうのはありつつも、どうしてもとりあえず置いておくっていうこともあります。
未だに見てもよくわからないシステム名が付いてて、本当に中身がよくわからないっていうのがあって、ここに一番下に書いてあるプロフェッサーXとベジタリアンというのは、これまで見たことがあるシステム名なんですが、中身がわかる名前をつけてくださいっていうのが、今日私が一番皆さんに言いたいことです。
 なんか愚痴っぽいことになりましたけど、前半のまとめとしては、
ユーザー価値を届けるための機械学習のプロジェクトに臨みましょう。
設計書とかドキュメンテーションも大事ですって話です。
今日のために頑張って用意してきた資料はここからなんですけど、LLMの推論っていうものを考えてみようっていう話を、今日後半っていうか残り25分でしていきたいと思います。
なんか愚痴っぽいことになりましたけど、前半のまとめとしては、
ユーザー価値を届けるための機械学習のプロジェクトに臨みましょう。
設計書とかドキュメンテーションも大事ですって話です。
今日のために頑張って用意してきた資料はここからなんですけど、LLMの推論っていうものを考えてみようっていう話を、今日後半っていうか残り25分でしていきたいと思います。
 でLLMっていうのが世の中に広まって、多分ここにいる方々は、何らかの形で使ってる方だと思うんですけど、使ってるつもりがなくても、GoogleとかiOSの後ろから使ってるってことはあると思うんですけど、LLMって一言に言って、すごい世の中で価値があるし、使うシステムに組み込むだったり、日々使うっていうことで考えてみたいツールっちゃツールなんですけど、じゃあ何をどういう風に使うのかというのは、やっぱりツール選定で重要だと思っております
でLLMっていうのが世の中に広まって、多分ここにいる方々は、何らかの形で使ってる方だと思うんですけど、使ってるつもりがなくても、GoogleとかiOSの後ろから使ってるってことはあると思うんですけど、LLMって一言に言って、すごい世の中で価値があるし、使うシステムに組み込むだったり、日々使うっていうことで考えてみたいツールっちゃツールなんですけど、じゃあ何をどういう風に使うのかというのは、やっぱりツール選定で重要だと思っております
 でLLMも一般的に使うにあたって、多分第一候補はChatGPTとかOpenAIのAPIだと思うんですよ。一番有名だから。で、かつ性能もそれなりに良いし、そもそもチャットが存在するので、なんか困ってて。とりあえずチャットでOpenAIのAPI側が本当にうまくいくのかをAPIにも継承できるっていうのは良いところだと思います。その一方で難点としてはカスタマイズが難しいとか、意外と障害率高い状態で使われることになる子とかと思います。
ツールとしては最近使って、これ便利と思うものには、Dify.aiっていうのがあって、これ本当使いやすいです。
カスタマイズが難しいっていうことをどうにかしたい。例えばデータだけでも自社のものを使いたい。
LLMに質問して返ってくるのって、基本的に一般的な回答だと思うので、そこに対して、例えば弊社の中の偉い人にどういうふうに説明してればいいのか教えてほしいと言われて、過去の資料を見ればわかるでしょ?みたいなことを言われたとすると、データは自分たちのものを用意しなきゃいけないので、その場合にRAGっていうのがRetrieval-Augmented Generationっていうのがある。
でLLMも一般的に使うにあたって、多分第一候補はChatGPTとかOpenAIのAPIだと思うんですよ。一番有名だから。で、かつ性能もそれなりに良いし、そもそもチャットが存在するので、なんか困ってて。とりあえずチャットでOpenAIのAPI側が本当にうまくいくのかをAPIにも継承できるっていうのは良いところだと思います。その一方で難点としてはカスタマイズが難しいとか、意外と障害率高い状態で使われることになる子とかと思います。
ツールとしては最近使って、これ便利と思うものには、Dify.aiっていうのがあって、これ本当使いやすいです。
カスタマイズが難しいっていうことをどうにかしたい。例えばデータだけでも自社のものを使いたい。
LLMに質問して返ってくるのって、基本的に一般的な回答だと思うので、そこに対して、例えば弊社の中の偉い人にどういうふうに説明してればいいのか教えてほしいと言われて、過去の資料を見ればわかるでしょ?みたいなことを言われたとすると、データは自分たちのものを用意しなきゃいけないので、その場合にRAGっていうのがRetrieval-Augmented Generationっていうのがある。
 で最後に自社で基盤モデルから学習するっていうので、LLMも作るっていうところになると、これはこれで大変っていうか、私、先々月くらいまで弊社のLLMで日本語版作ったりしたので、だいぶ大変っていうことがわかるんですけど、ただ、今だからこそできる技術的挑戦っちゃ挑戦なのでやってみるのはいいと思いますよ。それなりに面白い。
で最後に自社で基盤モデルから学習するっていうので、LLMも作るっていうところになると、これはこれで大変っていうか、私、先々月くらいまで弊社のLLMで日本語版作ったりしたので、だいぶ大変っていうことがわかるんですけど、ただ、今だからこそできる技術的挑戦っちゃ挑戦なのでやってみるのはいいと思いますよ。それなりに面白い。
Dify.aiって後ろ側は、OpenAIだったり、Google Geminiだったりするので、結局はそのそれらはパブリックなLLMも使ってるんですけど、データを突っ込むところを抽象化してくれるのは本当に便利なツールです。その一方でほとんどの会社で発生する課題としては、データを整理したり検索するところが結局難しい。データが整理されている会社は本当に見たことがないくらいです。そこを頑張ってくださいということになると思います。
ほとんどの用途、一般的な用途であれば上二つで足りるとは思いますが、ビジネスの中で本当にコンテキストや、データが重要になってくると、多分自社モデルっていうのを作るということになると思います。でLLMを使う場合、使い方としては公開されてるAPIとか、ChatGPTもしくはライブラリを使うかLangChainみたいな統合的なライブラリを使うと思います。
 個人的にこういったものを使う時は、例えばOpenAIのAPIだったら、JSON modeとかFunction Callingみたいな形でリクエストとレスポンスをJSONで構造化された状態にすることができるので、この辺は使った方が良い。一般的なソフトウェアを使って自然言語を入力して、正規表現でなんとか必要な情報を抜き出してくるっていうことを考え始めると、本当に面倒くさいだけです。
個人的にこういったものを使う時は、例えばOpenAIのAPIだったら、JSON modeとかFunction Callingみたいな形でリクエストとレスポンスをJSONで構造化された状態にすることができるので、この辺は使った方が良い。一般的なソフトウェアを使って自然言語を入力して、正規表現でなんとか必要な情報を抜き出してくるっていうことを考え始めると、本当に面倒くさいだけです。
OpenAIの最初のAPIあんまり好きじゃなかったけど、Function Callingが出た時は私はウオーって感じでした。
ただ、障害率は意外と高いのと、基本的にプロンプトとしてのリクエストよりもレスポンスの方が高い。このようになってるので、レスポンスがすごく長いようなシステムを作ると、OpenAI破産というか。LLMのお金がかかりすぎるということはあると思います。
どんどんDify.aiみたいなツールで解決されていくというか、抽象化されていくと思ってるので、それを待つってのも手だと思います。あと、これを作るということは人件費がかかるし、データを扱う以上、セキュリティは重要になってくるので、非機能要件が大事というところは覚えておいてください。
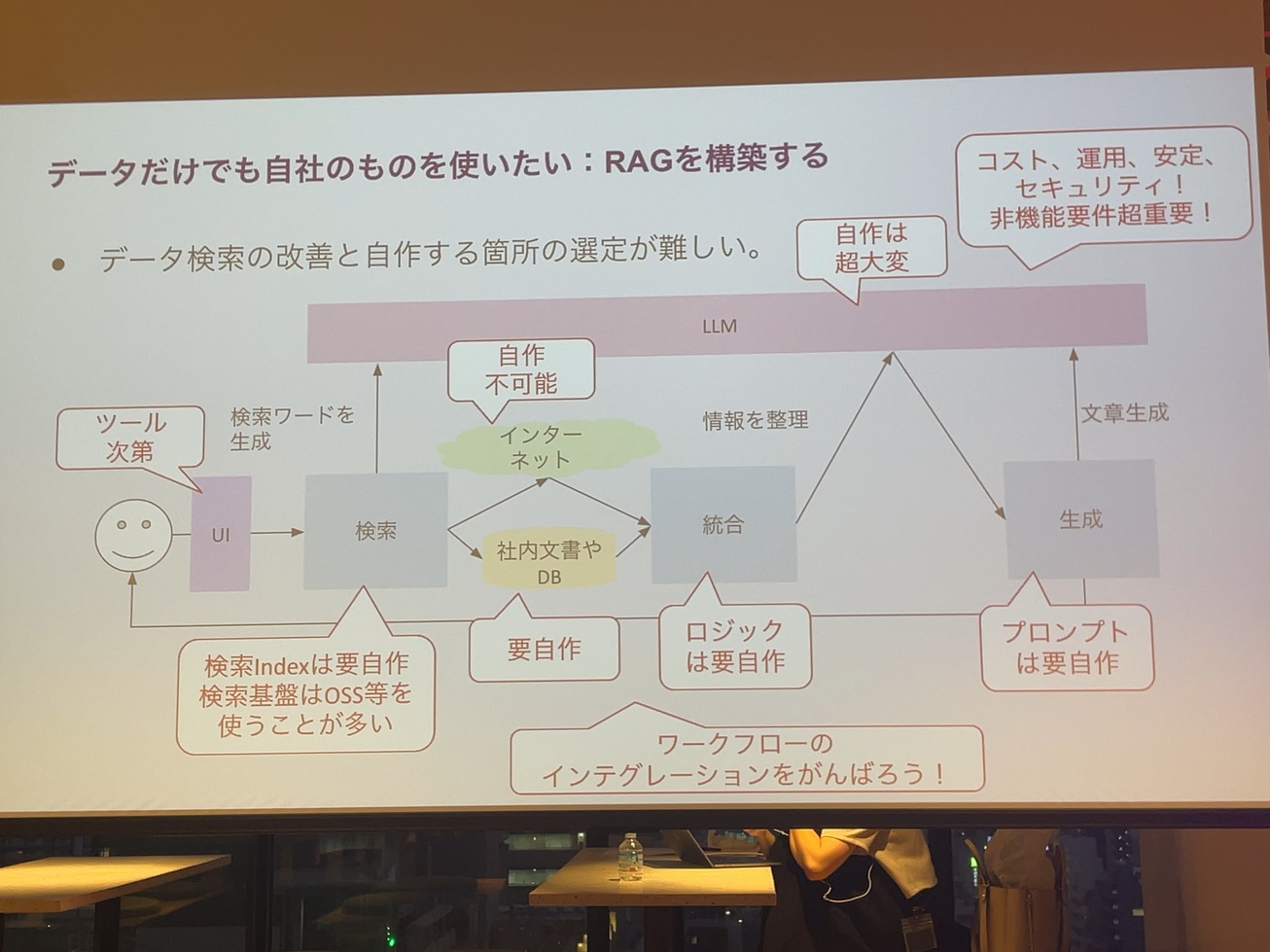 次にRAGの話で、RAGの場合はそもそも自分である程度作んなきゃいけないというのが多分課題だと思います。大まかにRAGの仕組みは検索したデータをまとめて、それを文書にしてユーザーに返す形だと思うんですが、検索のためのデータを整理する。インターネットから取ってくるというんのであれば、Surface APIみたいな使えばいいんですけど、社内の文書が必要な場合、その社内の文書っていうのは、例えばパワポになってたり、エクセルになってたり。アドビになったりPDFになってたりっていうもの、もしくは紙しかないっていうものをどうにかデジタル化するっていうのが課題になるとは思っております。あとはこの検索と整理して、それを生成するっていうところの流れっていうのをワークロードしてディベーションするっていうところが、頑張らなきゃいけない課題だと思うんですけど、その辺は
次にRAGの話で、RAGの場合はそもそも自分である程度作んなきゃいけないというのが多分課題だと思います。大まかにRAGの仕組みは検索したデータをまとめて、それを文書にしてユーザーに返す形だと思うんですが、検索のためのデータを整理する。インターネットから取ってくるというんのであれば、Surface APIみたいな使えばいいんですけど、社内の文書が必要な場合、その社内の文書っていうのは、例えばパワポになってたり、エクセルになってたり。アドビになったりPDFになってたりっていうもの、もしくは紙しかないっていうものをどうにかデジタル化するっていうのが課題になるとは思っております。あとはこの検索と整理して、それを生成するっていうところの流れっていうのをワークロードしてディベーションするっていうところが、頑張らなきゃいけない課題だと思うんですけど、その辺は
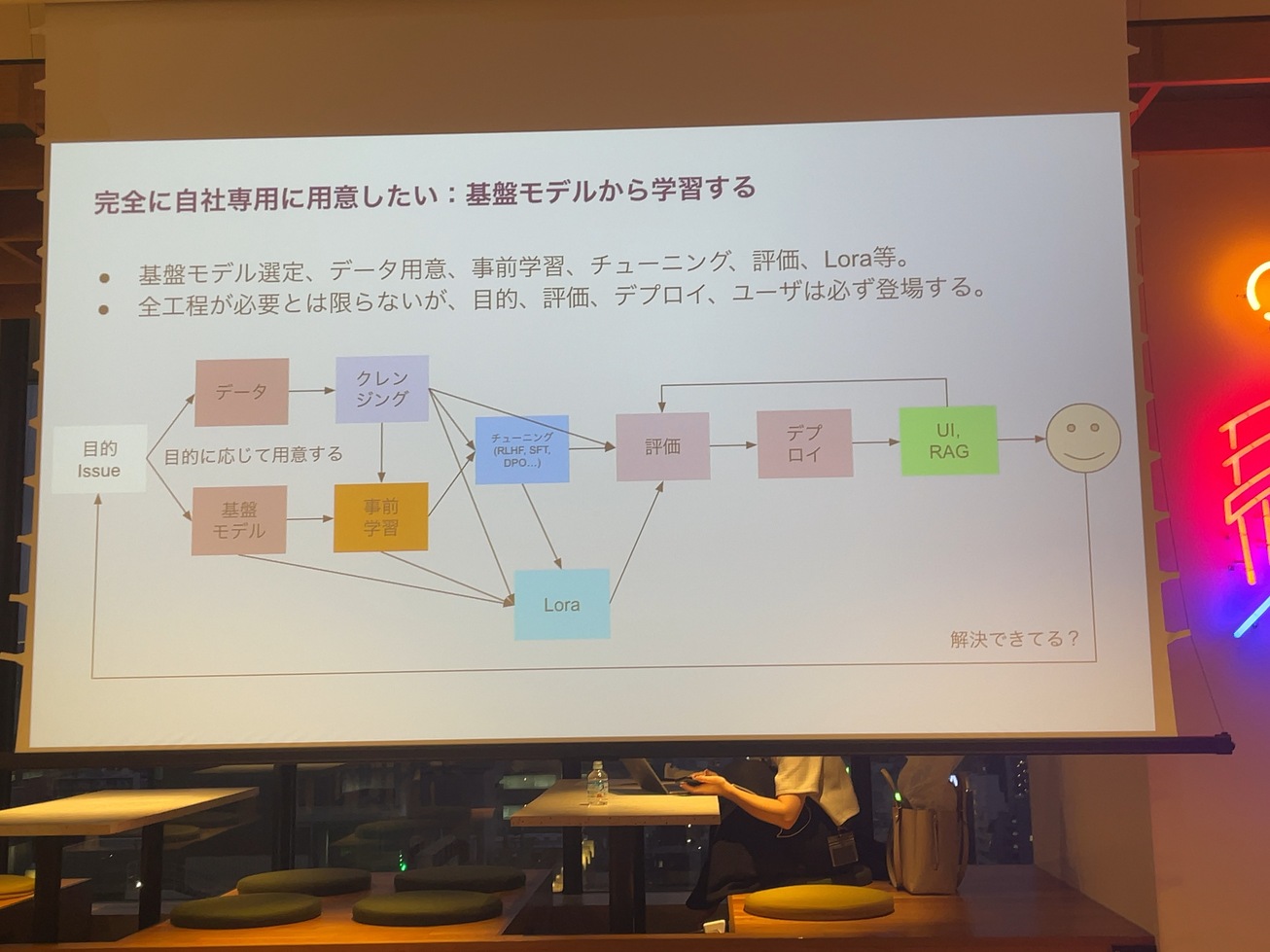 生成AIを自分たちで作るって話ですけど、目的を持った上でLLM学習した方がよいです。一年くらい前はとりあえず世の中に落ちてるデータを使って、モデルを作ったというのが主流だったと思います。それを作ったとしても、自社の中でそれ使うかっていうと、多分僕、AI使っちゃうんですよ。例えば日本の経済に強いLLMとか、カスタマーサービスに強いLLMとか、自分たちの課題に対して回答できるようなデータを用意して、その課題に対して評価するLLMの作り方をした方が、絶対ビジネスは伸びるし、使う側としてもわかりやすいと思います。
いずれにしても学習に対してデータを頑張って集めなきゃいけない。そしてそれを頑張ってクレンジングして、前処理したり、チューニングしたり、評価したりっていうことをやっていく。
生成AIを自分たちで作るって話ですけど、目的を持った上でLLM学習した方がよいです。一年くらい前はとりあえず世の中に落ちてるデータを使って、モデルを作ったというのが主流だったと思います。それを作ったとしても、自社の中でそれ使うかっていうと、多分僕、AI使っちゃうんですよ。例えば日本の経済に強いLLMとか、カスタマーサービスに強いLLMとか、自分たちの課題に対して回答できるようなデータを用意して、その課題に対して評価するLLMの作り方をした方が、絶対ビジネスは伸びるし、使う側としてもわかりやすいと思います。
いずれにしても学習に対してデータを頑張って集めなきゃいけない。そしてそれを頑張ってクレンジングして、前処理したり、チューニングしたり、評価したりっていうことをやっていく。
 はい、その作ったっていうのがこれ個人的な宣伝なんですけど、4、5月、ゴールデンウィークあたりに日本語の1.6Bモデルっていう。すごい小さいサイズのLLMを作りました。これ、Hugging Faceにありますのでもし興味ったら使ってください。GPU一個だけにも載る素晴らしいサイズなので、PU複数用意しなきゃいけない世の中のLLMよりも触り始めるにあたっては楽です。
https://ja.stability.ai/blog/japanese-stable-lm-2-16b
はい、その作ったっていうのがこれ個人的な宣伝なんですけど、4、5月、ゴールデンウィークあたりに日本語の1.6Bモデルっていう。すごい小さいサイズのLLMを作りました。これ、Hugging Faceにありますのでもし興味ったら使ってください。GPU一個だけにも載る素晴らしいサイズなので、PU複数用意しなきゃいけない世の中のLLMよりも触り始めるにあたっては楽です。
https://ja.stability.ai/blog/japanese-stable-lm-2-16b
 デプロイっていうことを考えてましょうって話なんですけど、そのデプロイっていうものを考えるにあたって、本当いろんなことを考えないといけません。
デプロイっていうことを考えてましょうって話なんですけど、そのデプロイっていうものを考えるにあたって、本当いろんなことを考えないといけません。
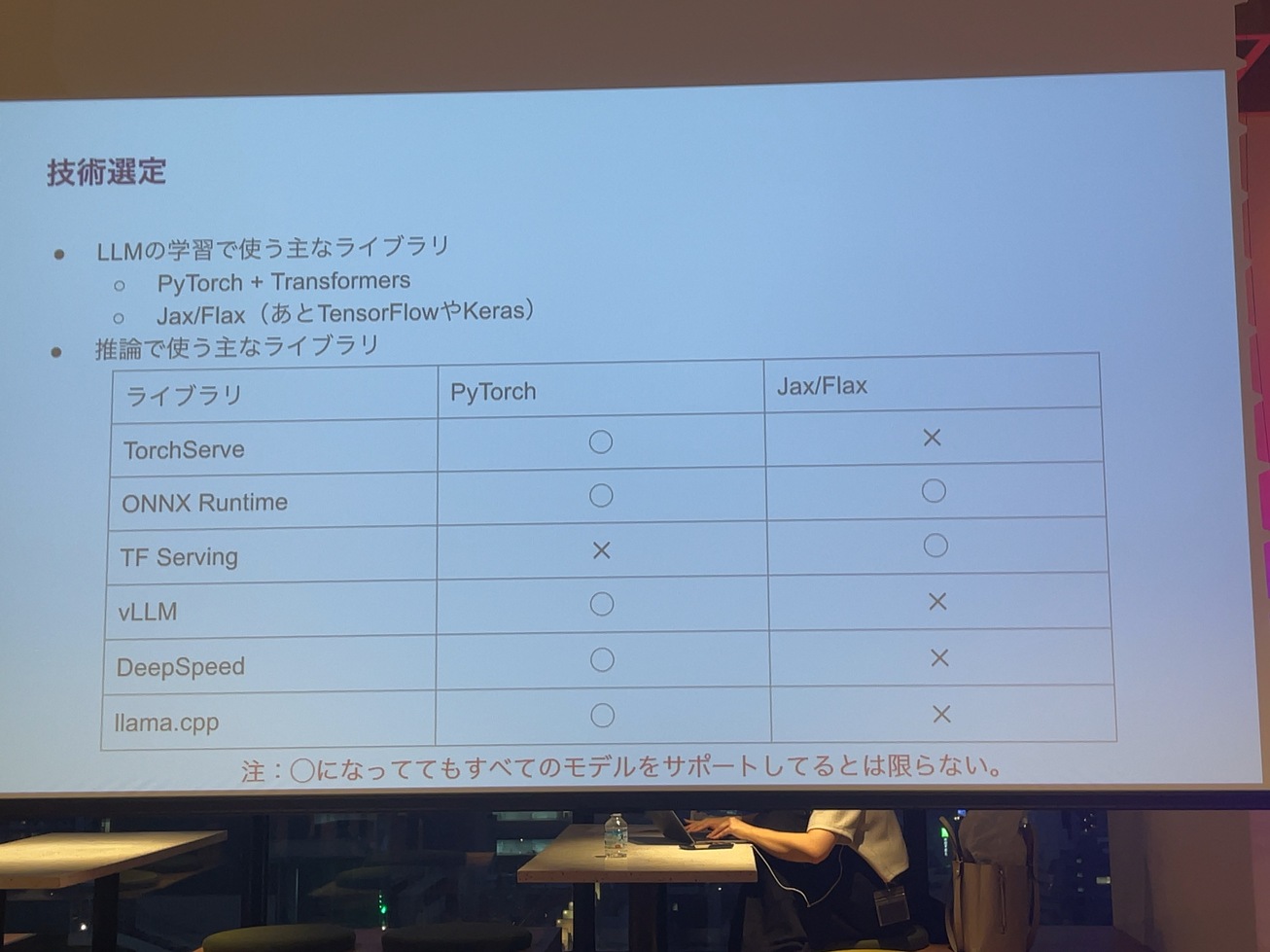 まずは技術選定ってところから始めるべきだと思ってます。モデルの学習に当たって、一般的なPyTorch+TransformersというのがLLMで学習する時の広く使われるライブラリの選定だと思います。それ以外にももちろんJax/Flaxとか。
まずは技術選定ってところから始めるべきだと思ってます。モデルの学習に当たって、一般的なPyTorch+TransformersというのがLLMで学習する時の広く使われるライブラリの選定だと思います。それ以外にももちろんJax/Flaxとか。
例えばPyTorchで学習したものについてはTF Serviceは使えないですし、逆にJax/Flaxで学習したものにはTorchServeは使えない。このvLLMとかDeepSpeedとかもサポートしてなかったりするはず。私が調べた限りはサポートないので結局、推論システムがちゃんと作れるライブラリ選んでいかないといけないっていうのは覚えておいて欲しいと思います。わかりやすくマルバツを書いてますが、これ実際、私がいろいろ試した結果分かったことです。
 推論で使えるライブラリや基盤は、学習時のモデルやライブラリに依存するということに集約されると思います。あと、GPUとこのライブラリだったらこのモデルは動くけど、このライブラリでCPUにしたら実は動かないものも、やってみたら意外とありました。具体的なライブラリの話をしながらしていきたいと思います。
推論で使えるライブラリや基盤は、学習時のモデルやライブラリに依存するということに集約されると思います。あと、GPUとこのライブラリだったらこのモデルは動くけど、このライブラリでCPUにしたら実は動かないものも、やってみたら意外とありました。具体的なライブラリの話をしながらしていきたいと思います。
今時点でLLMの学習をして推論をするという技術選定をするにあたって、一番無難なのはメジャーな機械計算基盤を選んでメジャーなライブライブを使ってメジャーなモデルを使うっていうなんかありきたりなものが私のおすすめです。 もちろん他のライブラリを使って、工夫するっていうのもあるとは思うんですけど、安全に行くんだったら、NvidiaのGPU使ってPyTorchとTransformersでやるっていうのがいいという気はしています。
 推論としてはバッチとPyTorchから推論っていうのがあって、
バッチによって推論する場合は大体は学習のプロセスはほぼ同じになるはずなので、その部分はそのまま難しいこと考えずに、学習のライブラリそのままで動かしてしまうっていうのも手だと思います。
PyTorchであれば、TorchスクリプトとかTorchコンパイルっていうものだけじゃなくて、学習でよく使えるAccelerrateをFlashAttentionとかDeepSpeedというものを使ってみると意外と速かったりするので、その辺は使いましょう。
推論としてはバッチとPyTorchから推論っていうのがあって、
バッチによって推論する場合は大体は学習のプロセスはほぼ同じになるはずなので、その部分はそのまま難しいこと考えずに、学習のライブラリそのままで動かしてしまうっていうのも手だと思います。
PyTorchであれば、TorchスクリプトとかTorchコンパイルっていうものだけじゃなくて、学習でよく使えるAccelerrateをFlashAttentionとかDeepSpeedというものを使ってみると意外と速かったりするので、その辺は使いましょう。
 レスポンシブの推論って話になってくるんですけど、今回話すために、この辺のTorchServeとvLLMとDeepSpeedとLLama.cpp全部触って、CPUとGPUでいろんなモデルを動かしてこれ動くのか動かないのか、みたいなことを今日話をさせていただきます。
レスポンシブの推論って話になってくるんですけど、今回話すために、この辺のTorchServeとvLLMとDeepSpeedとLLama.cpp全部触って、CPUとGPUでいろんなモデルを動かしてこれ動くのか動かないのか、みたいなことを今日話をさせていただきます。
 で、まずTorchServeはPyTorchが用意している推論のためのライブラリで。
RESTとgrpc両方起動可能です。起動する時の手順としては、PyTorchで学習したモデル.pthのファイルをtorch-model-archiverというCLIを通してモデル.marという名前のファイルに変換します。
ソースコードを見ると、torch-model-archiverでやってることはファイルを集めて全部アーカイブするというだけです。その他にドットpthというファイル、モデルのファイルと、前処理や推論の後処理を変えたhander.pyというファイルを入れて、TorchServeのコマンドで起動することができます。
で、まずTorchServeはPyTorchが用意している推論のためのライブラリで。
RESTとgrpc両方起動可能です。起動する時の手順としては、PyTorchで学習したモデル.pthのファイルをtorch-model-archiverというCLIを通してモデル.marという名前のファイルに変換します。
ソースコードを見ると、torch-model-archiverでやってることはファイルを集めて全部アーカイブするというだけです。その他にドットpthというファイル、モデルのファイルと、前処理や推論の後処理を変えたhander.pyというファイルを入れて、TorchServeのコマンドで起動することができます。
 TorchServeは意外とPyTorchのモデルだったら大体は動くものなんですけど、
使ってみてよかったのがまず複数バージョンのモデルを同時に起動できるので、
例えばABテストやりたいっていう時には便利です。DAGのワークフローを組めるというのは前のスライドの一番下にworkflow.marってあるんですけど、
モデルaの推論結果は、モデルbに入れてモデルbの結果をモデルCに入れて、結果にするというのを書くことができます。複雑なモデル間でやり取りするのを、マイクロバッチみたいなものを立ち上げる必要なく、一つのTorchServeの中で完結できるのはよかったと思っておいます。
TorchServeは意外とPyTorchのモデルだったら大体は動くものなんですけど、
使ってみてよかったのがまず複数バージョンのモデルを同時に起動できるので、
例えばABテストやりたいっていう時には便利です。DAGのワークフローを組めるというのは前のスライドの一番下にworkflow.marってあるんですけど、
モデルaの推論結果は、モデルbに入れてモデルbの結果をモデルCに入れて、結果にするというのを書くことができます。複雑なモデル間でやり取りするのを、マイクロバッチみたいなものを立ち上げる必要なく、一つのTorchServeの中で完結できるのはよかったと思っておいます。
 ライブラリのソースコード見てたらしれってあったのがマイクロバッジとかランキング処理っていうのも置いてあったりしたのでもうちょっとアピールしたらいいんじゃないかな。と思いましたね。
並列処理としてはPyTorchで、distributed.piplineっていうのが用意されていて、PiPPyはパイプラインパラレルのPyTorchというものの略なんですけど、複数のGPUにまたがって推論するっていう時のライブラリです。さっき6Bモデルが一つのGPUで動いたって、言いましたけど、普通に7Bモデルであるとか、14BモデルぐらいのサイズはすでにGPU、P4とかのサイズに乗らなかったりするのでランナーとして、GPUの中でモデルが立ち上がるって形になっております。
ライブラリのソースコード見てたらしれってあったのがマイクロバッジとかランキング処理っていうのも置いてあったりしたのでもうちょっとアピールしたらいいんじゃないかな。と思いましたね。
並列処理としてはPyTorchで、distributed.piplineっていうのが用意されていて、PiPPyはパイプラインパラレルのPyTorchというものの略なんですけど、複数のGPUにまたがって推論するっていう時のライブラリです。さっき6Bモデルが一つのGPUで動いたって、言いましたけど、普通に7Bモデルであるとか、14BモデルぐらいのサイズはすでにGPU、P4とかのサイズに乗らなかったりするのでランナーとして、GPUの中でモデルが立ち上がるって形になっております。
そういった小さいはずのサイズでもちゃんと動かすそうとすると複数のGPUを用意しなきゃいけなくて、それらに跨ってGeForceに持ち込まないといけないので、やっぱりそれをやる仕組みがありました。そのPiPPyの構成としては、PyTorchの方で用意されているプログラムをそのまま持ってきてるんですけど、フロントエンドがあってスポーナーがあって、ランナーがあるって形です。Frontendはモデルを呼び込むところで、ちょうどモデルを呼び込むところでモデルをオープンして、データの流れを解析してモデルを分割してくれます。torchrunコマンドで、その分割されたモデルを各GPUに割り合てます。
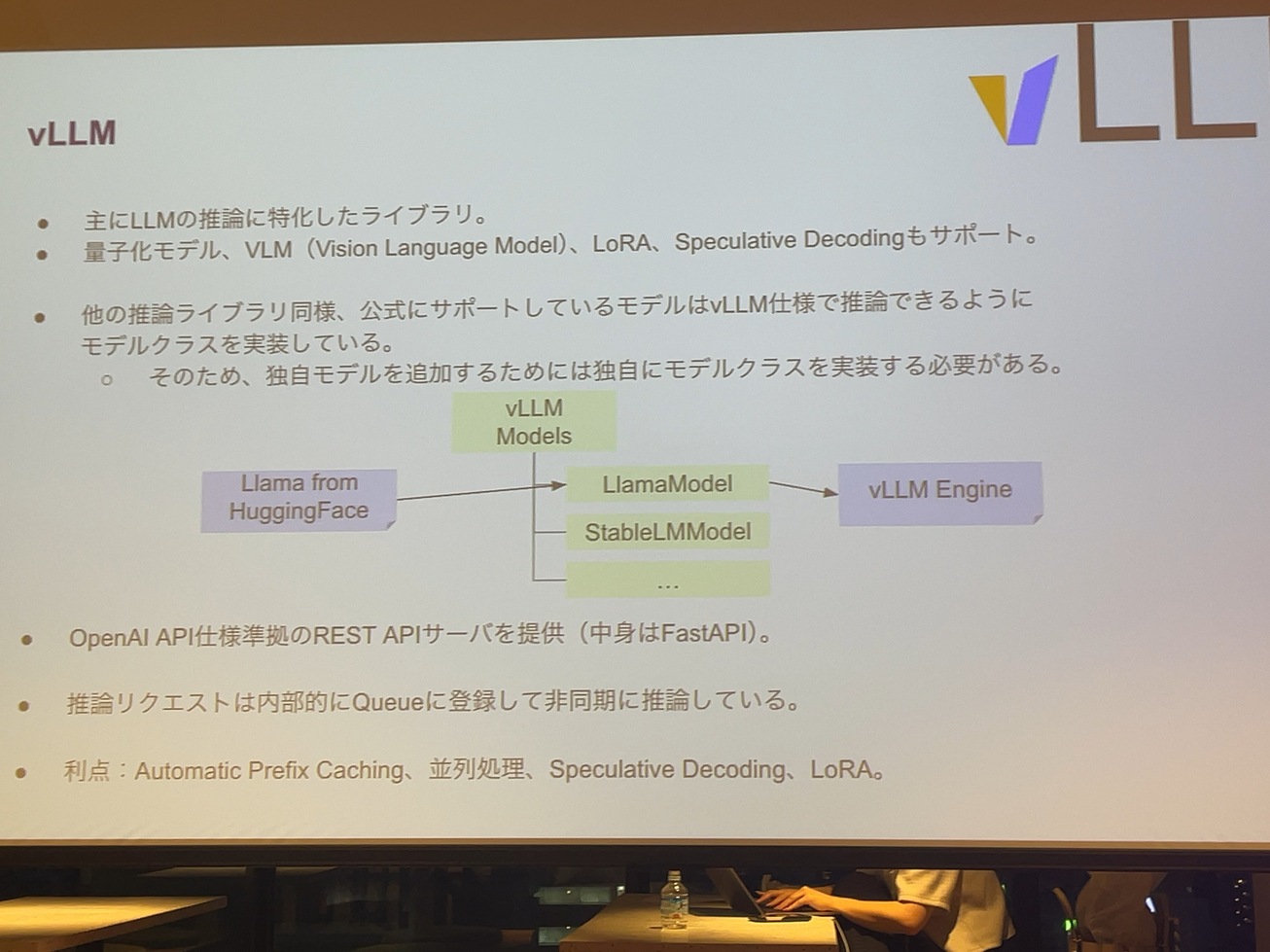 次にvLLMで、これはTorchServeは別にLLMに限らずPyTorch全般で推論するためのライブラリなんですけど、vLLMはLLMに特化した推論のためのライブラリになっています。量子化とかLLMとか言いつつ、ビジョンランゲージモデルをサポートしてたり、なんとかLoRAであるとか、Speculativeみたいなものをサポートしたライブラリです。
次にvLLMで、これはTorchServeは別にLLMに限らずPyTorch全般で推論するためのライブラリなんですけど、vLLMはLLMに特化した推論のためのライブラリになっています。量子化とかLLMとか言いつつ、ビジョンランゲージモデルをサポートしてたり、なんとかLoRAであるとか、Speculativeみたいなものをサポートしたライブラリです。
vLLMもそうだし、Llama.cppもそうなんですけど、実はサポートしているモデルはちゃんと決まっていて、そのサポートしているモデルは何を持ってサポートしているのかっていうと、VLMでモデルを読み込む時に、そのモデルのクラスがVLMの中にちゃんと書いてあって。例えばLlammaModelであるとか、QBモデルだったら、このクラスに載せ替えるっていうことをやってたりします。モデルのウェイトをvLLMが都合がいい形に読み込んでいて、各LLMのモデルのための独自クラスを作ってたりします。作った人が頑張ってくださったというか、すげえなっていう感じです。それは言い換えると、自分で作った言語モデルって、実はvLLMに乗らないし、自分でそのvLLMに載せるためのクラスを作っていうのは、その辺の拡張性はちょっと難しかったりします。
 vLLMの中を調べて面白かったのがAutomatic Prefix Castingっていう機構があって、これは推論のためのキャッシュっていうのを取っておいて、推論を高速化するっていう仕組みです。
何をキャッシュしてるのかっていうと、トランスフォーマーで推論するときにプロンプトが入っていて、それをKVキャッシュに変換して、そしてKVキャッシュを元に出力となるトークンの文書を作ってくれて、そデコードの部分はくるくる回るっていうような仕組みなんですけど、
プロンプトからPrefillしてKVキャッシュを作るっていう部分をキャッシュしてるっていう形です。例えばRAGとかで長文のドキュメント読ませて質問しますと。また同じ長文のドキュメントを読み込ませて質問します。みたいな使い方ってよくやるパターンですけど、その長文のドキュメントって、毎回同じ処理をする部分は、絶対前半の部分は無駄なので、プロックに分割してキャッシュしておいて、KVキャッシュを同じ文書が来たら使うというような仕組みです。他にも例えばチャットUIで過去のチャットの履歴を使って、次の文章を書く。チャットキャッシュ、チャット履歴って必ずほぼ同じものが伝わるはずなので、そこの部分を KVキャッシュで賄うような仕組みになっています。
vLLMの中を調べて面白かったのがAutomatic Prefix Castingっていう機構があって、これは推論のためのキャッシュっていうのを取っておいて、推論を高速化するっていう仕組みです。
何をキャッシュしてるのかっていうと、トランスフォーマーで推論するときにプロンプトが入っていて、それをKVキャッシュに変換して、そしてKVキャッシュを元に出力となるトークンの文書を作ってくれて、そデコードの部分はくるくる回るっていうような仕組みなんですけど、
プロンプトからPrefillしてKVキャッシュを作るっていう部分をキャッシュしてるっていう形です。例えばRAGとかで長文のドキュメント読ませて質問しますと。また同じ長文のドキュメントを読み込ませて質問します。みたいな使い方ってよくやるパターンですけど、その長文のドキュメントって、毎回同じ処理をする部分は、絶対前半の部分は無駄なので、プロックに分割してキャッシュしておいて、KVキャッシュを同じ文書が来たら使うというような仕組みです。他にも例えばチャットUIで過去のチャットの履歴を使って、次の文章を書く。チャットキャッシュ、チャット履歴って必ずほぼ同じものが伝わるはずなので、そこの部分を KVキャッシュで賄うような仕組みになっています。
 あとは処理としてはTensor Parallelっていうやり方を使ってるとか、パラレルに処理するにあたって、もちろんGPU間での通信は必要になるんですけど、GPU間の通信のために、Nvidiaのニッケル(NCCL)っていうのって、NvidiaのCUDAとか、インストールして、サーバーの中で使ってる定番で、よく見かけるライブラリですけど、Nvidia Collective Communications Livraryっていう。GPU間の通信をするためのライブラリがあって、それをPythonでラップしたPyNcclというのを作ってたりして、涙ぐらしい努力が伺えるようなものが含まれています。
文章をドラフトモデルで作らせた後にターゲットモデルの方でこれ、猫だから書き直すみたいなことをやってくれるっていうような、仕組みらしいです。これをvLLMの方ですでにサポートしているので、ドラフトモデルとターゲットモデルを用意しておけば、そのまま使えるっていうふうになっています。実際に動かすことができました。
あとは処理としてはTensor Parallelっていうやり方を使ってるとか、パラレルに処理するにあたって、もちろんGPU間での通信は必要になるんですけど、GPU間の通信のために、Nvidiaのニッケル(NCCL)っていうのって、NvidiaのCUDAとか、インストールして、サーバーの中で使ってる定番で、よく見かけるライブラリですけど、Nvidia Collective Communications Livraryっていう。GPU間の通信をするためのライブラリがあって、それをPythonでラップしたPyNcclというのを作ってたりして、涙ぐらしい努力が伺えるようなものが含まれています。
文章をドラフトモデルで作らせた後にターゲットモデルの方でこれ、猫だから書き直すみたいなことをやってくれるっていうような、仕組みらしいです。これをvLLMの方ですでにサポートしているので、ドラフトモデルとターゲットモデルを用意しておけば、そのまま使えるっていうふうになっています。実際に動かすことができました。
Speculative Decodingっていうのがexperimentalであるんですけど、最近Elizaさんが出したテックブログでElizaさんのチャットのLLMのバックエンドにこのSpeculative Decodingっていうのを使ってるっていうのを見かけて、こんなのあるんだってちょっと驚いたんですけど、これってトークナイザを共有したドラフトモデルとターゲットモデルで、本来はターゲットモデルで推論したいんですけど、それが重くて処理を早くしたいっていう時に、同じトークンの間で推論するドラフトモデルという小さいモデルの方で文章を作っておいて、その作った文章のトークンに対してこれオッケー、これNGみたいなことをしています。
 続いてDeepSpeedのこちらはMicrosoftが出しているModel implementations for Inferenceとかその他もろもろ含めて、高速化するためのライブラリです。
学習だけじゃなくて、推論の方についてもいろいろと工夫されてるのでピックアップすると一つ目がDeep fusionというもので、
例えばニューラルネットワークの巨大な計算も、リソースの中でelement-wise opelationと呼ばれるような加算とか乗算とか簡略してしまえる処理っていうのはたくさんあると思うんですけど、それをやる上でのGPUとのボトムネックが、計算よりもメモリアクセスの部分が課題で、その手順としてはメモリからデータ読んで演算して、足し算してメモリーに書き出すのを見てると何100万回とやってるので、その部分の
続いてDeepSpeedのこちらはMicrosoftが出しているModel implementations for Inferenceとかその他もろもろ含めて、高速化するためのライブラリです。
学習だけじゃなくて、推論の方についてもいろいろと工夫されてるのでピックアップすると一つ目がDeep fusionというもので、
例えばニューラルネットワークの巨大な計算も、リソースの中でelement-wise opelationと呼ばれるような加算とか乗算とか簡略してしまえる処理っていうのはたくさんあると思うんですけど、それをやる上でのGPUとのボトムネックが、計算よりもメモリアクセスの部分が課題で、その手順としてはメモリからデータ読んで演算して、足し算してメモリーに書き出すのを見てると何100万回とやってるので、その部分の
 かけて足して地方に利用するのを一つのまとめるっていうのがフュージョンっていう技術です。
これ自体は実はTorch jitとか、TorchCompileみたいなもの中でサポートされたりするので学習済みのTorchのモデルとかをTorch jitでjit compileされるはずなんですけど、DeepSpeedのDeep Fusionの中では、その合成済みの演算とか、複数のレイヤーも一つの一つの大きな演算として構成することが可能だそうです。
実態としてはQKVとかアAttentionみたいなトランスフォーマーの中で必ず発生する計算というのを1.5倍とか高速化できるというのがこの状態です。
かけて足して地方に利用するのを一つのまとめるっていうのがフュージョンっていう技術です。
これ自体は実はTorch jitとか、TorchCompileみたいなもの中でサポートされたりするので学習済みのTorchのモデルとかをTorch jitでjit compileされるはずなんですけど、DeepSpeedのDeep Fusionの中では、その合成済みの演算とか、複数のレイヤーも一つの一つの大きな演算として構成することが可能だそうです。
実態としてはQKVとかアAttentionみたいなトランスフォーマーの中で必ず発生する計算というのを1.5倍とか高速化できるというのがこの状態です。
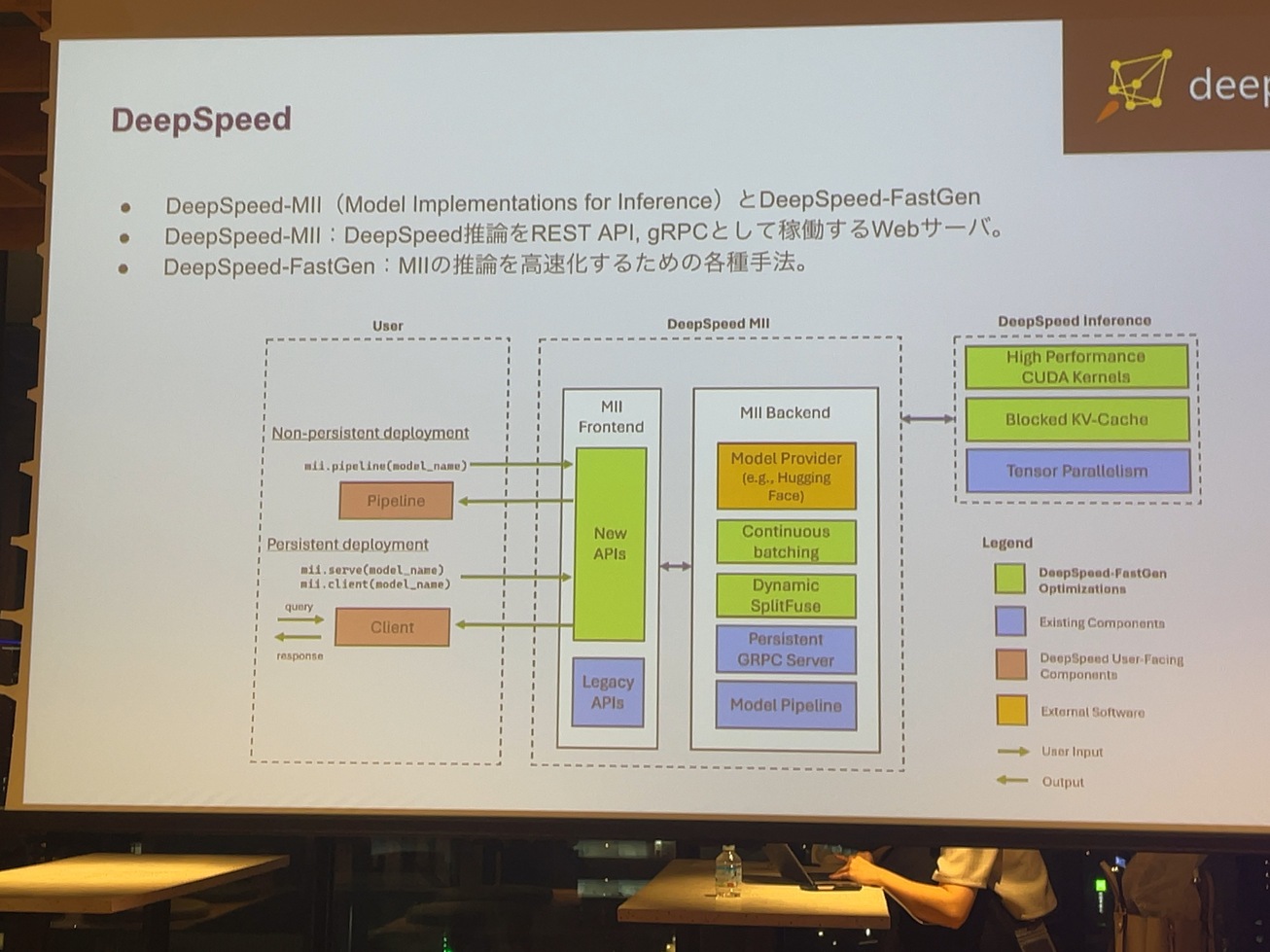 ここまで話したのは、あくまでPythonの中でモデルを読み込んで、DeepSpeedで推論するだけです。それをWebサーバーとして起動するでDeepSpeed MIIっていうのと、DeepSpeed-FastGenというのがあります。DeepSpeed MIIはModel Inplementations for Inforenceっていうものの略称なんですけど、ソースコード見たら普通にPython gRPCが動いたり、REST APIだとかが動いているんですけど、FastGenの方がいろいろと面白いことやってて、KVキャッシュのメモリフラグメンテーションを解消したり、プロンプトのサイズをいい感じにして、バッチのサイズを調整してたりします。
ここまで話したのは、あくまでPythonの中でモデルを読み込んで、DeepSpeedで推論するだけです。それをWebサーバーとして起動するでDeepSpeed MIIっていうのと、DeepSpeed-FastGenというのがあります。DeepSpeed MIIはModel Inplementations for Inforenceっていうものの略称なんですけど、ソースコード見たら普通にPython gRPCが動いたり、REST APIだとかが動いているんですけど、FastGenの方がいろいろと面白いことやってて、KVキャッシュのメモリフラグメンテーションを解消したり、プロンプトのサイズをいい感じにして、バッチのサイズを調整してたりします。
 この最後のDeepSpeedのContinuous Batchingも面白い工夫だと思います。学習の時にバッチ学習で例えば、文章として四つとか、八つとか、16を一気に学習させるのは、LLMに限らず、よくやると思います。推論するときにリクエストが来たら、それに対してレスポンス回数は、バッチのサイズとか気にせずにレスポンシブに返すだけじゃなく、バッチサイズが決まってるんだから八つのサイズがあるバッチに対してリクエストが来たら、キューを貯めてスケジューリングして、リクエストに対してレスポンスを返すっていうようなDynamic batchingというような仕組みがあります。今日の話の途中で間にキューを立てるって話しましたけど、そこで高速化するという本当に推論早くするうえで、いろんな工夫をしていますね。
この最後のDeepSpeedのContinuous Batchingも面白い工夫だと思います。学習の時にバッチ学習で例えば、文章として四つとか、八つとか、16を一気に学習させるのは、LLMに限らず、よくやると思います。推論するときにリクエストが来たら、それに対してレスポンス回数は、バッチのサイズとか気にせずにレスポンシブに返すだけじゃなく、バッチサイズが決まってるんだから八つのサイズがあるバッチに対してリクエストが来たら、キューを貯めてスケジューリングして、リクエストに対してレスポンスを返すっていうようなDynamic batchingというような仕組みがあります。今日の話の途中で間にキューを立てるって話しましたけど、そこで高速化するという本当に推論早くするうえで、いろんな工夫をしていますね。
生成される文章が長文になる部分がボトルネックになるので、Dynamic batchingだと遅くなるというような課題があって、一回のトークン生成ごとにバッチを作り直して、そこに空いてるものに対して新しいリクエストを組み込むということをやってるのがContinuous batchingです。それって本当にバッチなのかっていうのはありますが。
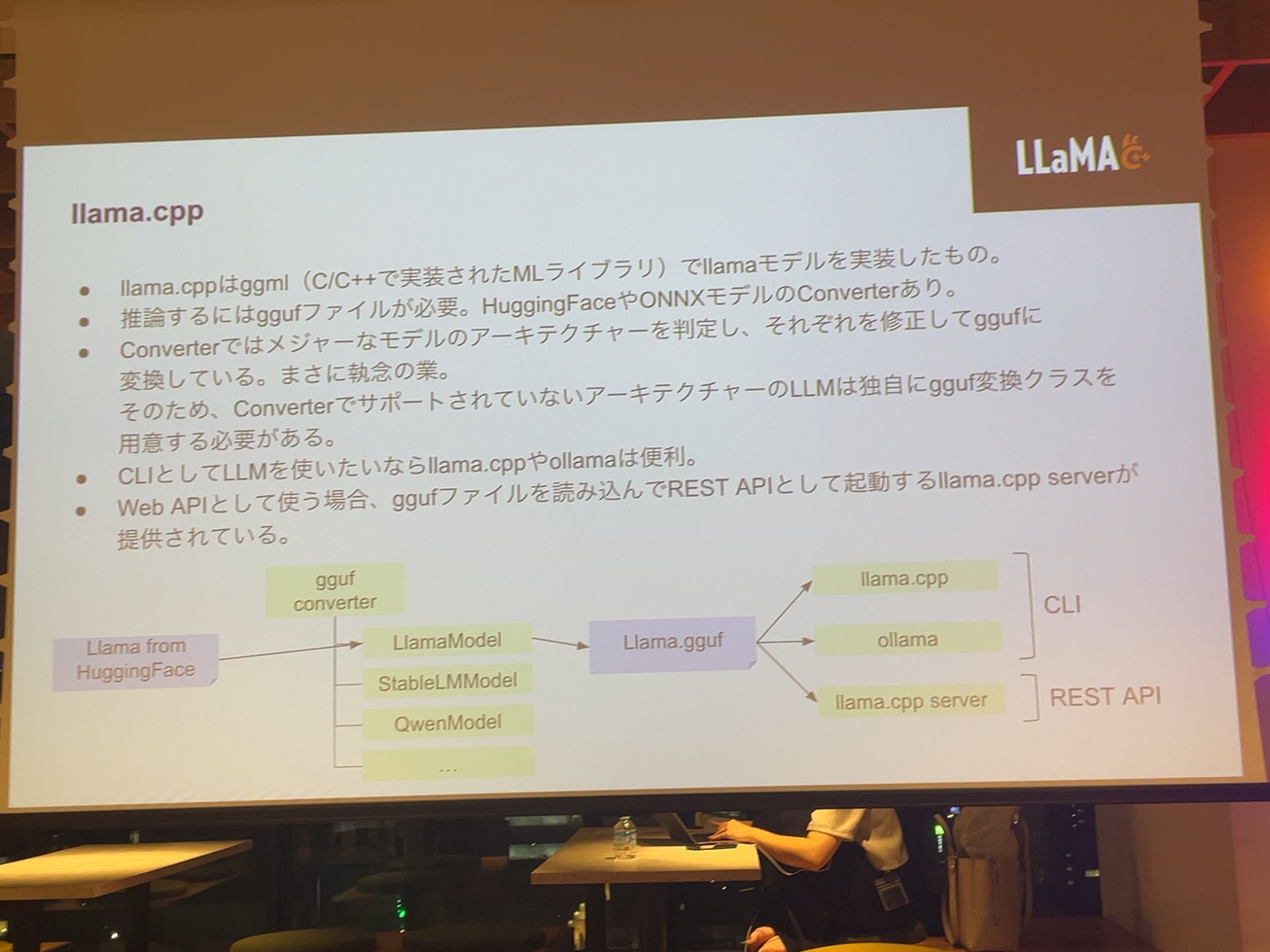 最後にllama.cpp。Ollamaっていう形でllama.cppを内部的に使用したものを使ってると思うんですけど、llama.cppはcppって書いてある通り、CとかC++で書かれたMLのライバルにggufっていうのがあって、これを名前をモデルを動かすためにGMの作者が作っておかないCPPになっております。CとかC++ということは、PyTorchのモデルがそのまま動くってことは絶対になくって、そのPyTorchのモデルとやっぱりCとかC++で読み込ませるっていうか、cgmaで読み込ませるためにggufっていうファイルに変換する必要がありますとVLMのところにも話しましたけど、そこにはやっぱりコンバーターがあってコンバーターっていうのの中身を見ると、ひたすらクラスモデルがあって、ラマのモデルはこういう風に書き直す。VPN QAのモデルはこういうふうに書き直すっていうのが書かれているっていうんで本当にLLMの推論の部分を頑張ってる人達って、涙ぐましいようなことに今やってるっていうのは、このollamaとかCLIとかREST APIを使ってllama.cpp.server実は密かにサーバーというのがあって、WebAPを立ち上げることもできたりします。
最後にllama.cpp。Ollamaっていう形でllama.cppを内部的に使用したものを使ってると思うんですけど、llama.cppはcppって書いてある通り、CとかC++で書かれたMLのライバルにggufっていうのがあって、これを名前をモデルを動かすためにGMの作者が作っておかないCPPになっております。CとかC++ということは、PyTorchのモデルがそのまま動くってことは絶対になくって、そのPyTorchのモデルとやっぱりCとかC++で読み込ませるっていうか、cgmaで読み込ませるためにggufっていうファイルに変換する必要がありますとVLMのところにも話しましたけど、そこにはやっぱりコンバーターがあってコンバーターっていうのの中身を見ると、ひたすらクラスモデルがあって、ラマのモデルはこういう風に書き直す。VPN QAのモデルはこういうふうに書き直すっていうのが書かれているっていうんで本当にLLMの推論の部分を頑張ってる人達って、涙ぐましいようなことに今やってるっていうのは、このollamaとかCLIとかREST APIを使ってllama.cpp.server実は密かにサーバーというのがあって、WebAPを立ち上げることもできたりします。
 あと、LLMを推論として使う時に、重要なこととして不適切なリクエストの対処です。今日、最初の方でNejumiリーダーボードに、そういった評価を追加するというのがあったと思うんですけど、まさにそれと同じで、爆弾の作り方を教えてください。に対して本当に爆弾の作り方を教えるのは、法律に触れるかどうか分かりませんが、サービスとしては微妙ですよね。その辺の対処っていうのは重要なところだし、ハルシネーションもなんとかしなきゃいけないので、ファイチューニングで学習するのが一つ
あと、LLMを推論として使う時に、重要なこととして不適切なリクエストの対処です。今日、最初の方でNejumiリーダーボードに、そういった評価を追加するというのがあったと思うんですけど、まさにそれと同じで、爆弾の作り方を教えてください。に対して本当に爆弾の作り方を教えるのは、法律に触れるかどうか分かりませんが、サービスとしては微妙ですよね。その辺の対処っていうのは重要なところだし、ハルシネーションもなんとかしなきゃいけないので、ファイチューニングで学習するのが一つ
 あとは処理量をどう考えるのかっていうのが一つ。やっぱり一般的なWebサーバーだったら、リクエストパーセコンド(RPS)でリクエストに対する量の設計をするとは思うんですけど、遅いのはそのトークンの生成が終わるまでデコーダーがずんずん回ってる部分で、つまりはリクエストに対して、トークンはどれくらい生成されるのかを測らないと、結局、アプリインフラレベルの設計になる。その辺を例えばDataDogとかに、連携して考えないと。インフラエンジニアとしてインフラの設計する時に、RPS低いのになんでこんなに遅いんだ?みたいなことが発生する課題だと思っています。
あとは処理量をどう考えるのかっていうのが一つ。やっぱり一般的なWebサーバーだったら、リクエストパーセコンド(RPS)でリクエストに対する量の設計をするとは思うんですけど、遅いのはそのトークンの生成が終わるまでデコーダーがずんずん回ってる部分で、つまりはリクエストに対して、トークンはどれくらい生成されるのかを測らないと、結局、アプリインフラレベルの設計になる。その辺を例えばDataDogとかに、連携して考えないと。インフラエンジニアとしてインフラの設計する時に、RPS低いのになんでこんなに遅いんだ?みたいなことが発生する課題だと思っています。
 あとは今日、ここまで話したのは、Pythonとかサーバーサイドっていうことについて話していたんですけど、実は別にPythonでもなければ、自サイトでやりたいっていう人もいて、今日山口さんが多分デプロイのところで言ってくれのを楽しみに来たんですけど。一番簡単な方法としてはONNXに変換することだと思ってます。HuggingFaceがOptimum CLIでLLMをONNXに変換するツールを提供していたりするので、それを使うのは手です。ただし実際使ってみてGPUの場合、一部のモデルが変換できなかったり、CPUもほとんどNGだったりしてたので意外と皆無です。あとは個人のために学習し直したモデルを、自分のスマホの中で動かすっていうのはロマンがあるので、個人的にはやりたいなっていう気がしています。
あとは今日、ここまで話したのは、Pythonとかサーバーサイドっていうことについて話していたんですけど、実は別にPythonでもなければ、自サイトでやりたいっていう人もいて、今日山口さんが多分デプロイのところで言ってくれのを楽しみに来たんですけど。一番簡単な方法としてはONNXに変換することだと思ってます。HuggingFaceがOptimum CLIでLLMをONNXに変換するツールを提供していたりするので、それを使うのは手です。ただし実際使ってみてGPUの場合、一部のモデルが変換できなかったり、CPUもほとんどNGだったりしてたので意外と皆無です。あとは個人のために学習し直したモデルを、自分のスマホの中で動かすっていうのはロマンがあるので、個人的にはやりたいなっていう気がしています。
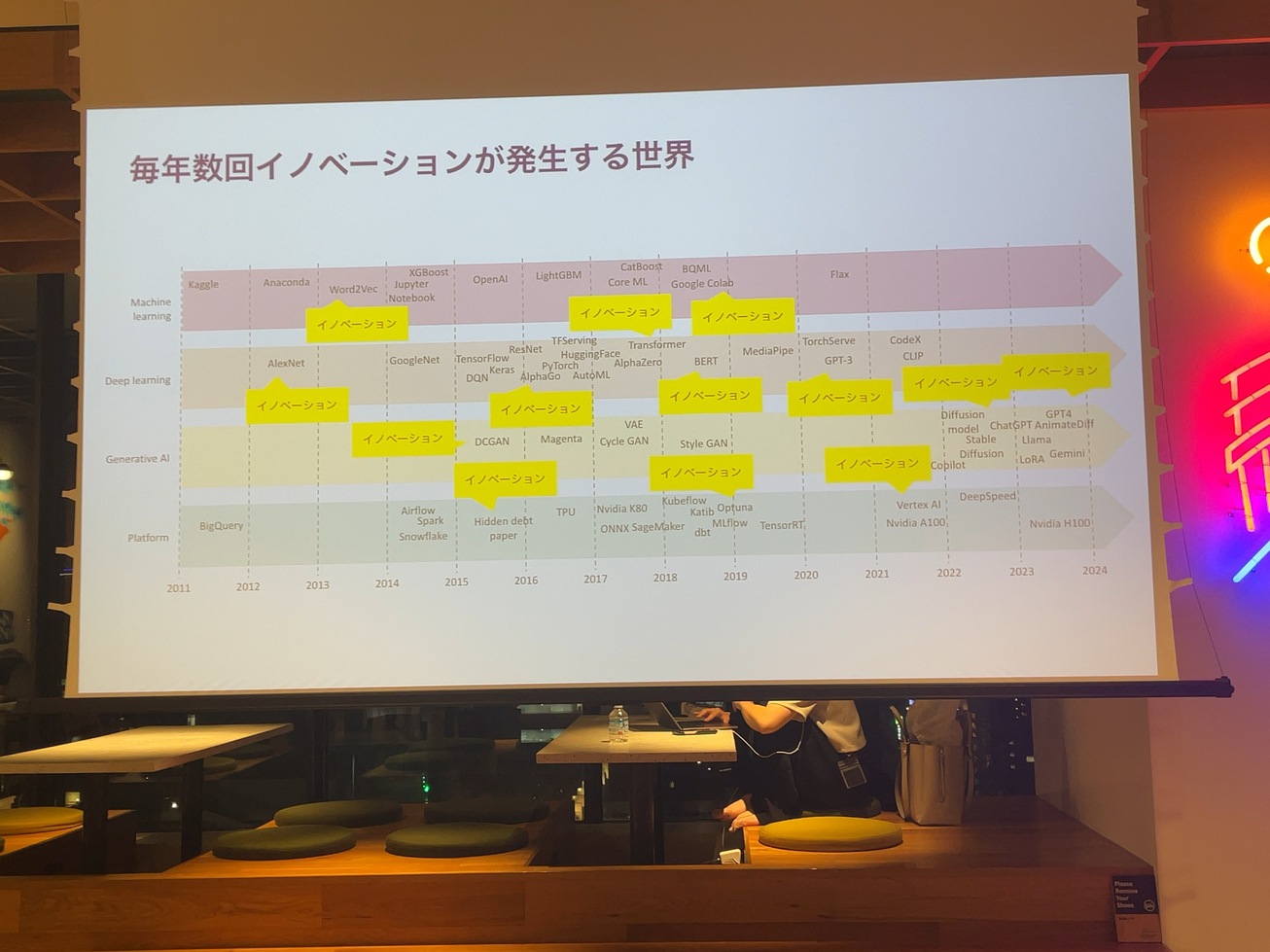 AIの世界は年数回イノベーションが発生する感じでAlexNetって皆さんご存知ですか?12年くらい前に出たconvolution networkが世の中に広まったきっかけです。
たった12年でまさかAIによって文章が人間と同じくらい自然に書かれるようになることを想像した人がどれだけいたのかって感じなんですけど、今やそこからさらに新しい世界が開けていくような世の中にみんな生きてると思います。いずれにしても作ったものの運用は、常に発生する課題なので、DevOpsっていう観点で作ったもののメトリックスを取って、世の中にユーザーに価値を与えるところから、技術選定を設計しなきゃいけないことは変わらないと思っています。
AIの世界は年数回イノベーションが発生する感じでAlexNetって皆さんご存知ですか?12年くらい前に出たconvolution networkが世の中に広まったきっかけです。
たった12年でまさかAIによって文章が人間と同じくらい自然に書かれるようになることを想像した人がどれだけいたのかって感じなんですけど、今やそこからさらに新しい世界が開けていくような世の中にみんな生きてると思います。いずれにしても作ったものの運用は、常に発生する課題なので、DevOpsっていう観点で作ったもののメトリックスを取って、世の中にユーザーに価値を与えるところから、技術選定を設計しなきゃいけないことは変わらないと思っています。
 LLMによってイノベーションは加速していますけど、今日の資料を作るのに、いろんなドキュメントをGoogle NoteBookLMのにひたすら読み込ませて、要約してもらいました。意外と便利です。LLMによって新技術のキャッチアップって簡単になっているので、変化が激しいですけど、追随するのも意外と楽になってきてるので、「俺たちの戦いは、これからだ」ということで今日の話はまとめたいと思います。
LLMによってイノベーションは加速していますけど、今日の資料を作るのに、いろんなドキュメントをGoogle NoteBookLMのにひたすら読み込ませて、要約してもらいました。意外と便利です。LLMによって新技術のキャッチアップって簡単になっているので、変化が激しいですけど、追随するのも意外と楽になってきてるので、「俺たちの戦いは、これからだ」ということで今日の話はまとめたいと思います。
 あと宣伝なんですけど。デブサミ夏7月23日、24日、こちら登壇しますので、もしよかったらご参加ください。東京駅の近く、多分この辺でやります。
あと宣伝なんですけど。デブサミ夏7月23日、24日、こちら登壇しますので、もしよかったらご参加ください。東京駅の近く、多分この辺でやります。
 あと、弊社の宣伝ですけど、Stable Diffusion 3っていうすごい画像を作るのが得意なモデルを出しましたので、もしよかったら使っているだけと幸いです。ありがとうございました。
あと、弊社の宣伝ですけど、Stable Diffusion 3っていうすごい画像を作るのが得意なモデルを出しましたので、もしよかったら使っているだけと幸いです。ありがとうございました。
「Heron VLMリーダーボードのご紹介」 山本 祐也さん
Heron VLMリーダーボード短縮URL http://vlm.nejumi.ai/
 まず、私。Weighs & Biases、当社で機械学習エンジニアをしております。山本と申します。ちょっと最近全然入れてないんですけども、Kagglerをやっております。今回リーダーボードも、もともとはといえば学会でチューリング井上さんにお会いして彼らがHeron Benchmarkを作って、これをリーダーボードにして運営するともっと面白くなるんじゃないかなみたいな話で懇親会に盛り上がったのがきっかけです。あと、このkaggleについて書いた、でまた関係があるという内容です。
まず、私。Weighs & Biases、当社で機械学習エンジニアをしております。山本と申します。ちょっと最近全然入れてないんですけども、Kagglerをやっております。今回リーダーボードも、もともとはといえば学会でチューリング井上さんにお会いして彼らがHeron Benchmarkを作って、これをリーダーボードにして運営するともっと面白くなるんじゃないかなみたいな話で懇親会に盛り上がったのがきっかけです。あと、このkaggleについて書いた、でまた関係があるという内容です。
 弊社のネズミリーダーボードという、私のkaggle名に由来してるんですけれども、運営しております。今回もヘロンの背中に乗ってということで、こんなバナーカードになっていたりします。
弊社のネズミリーダーボードという、私のkaggle名に由来してるんですけれども、運営しております。今回もヘロンの背中に乗ってということで、こんなバナーカードになっていたりします。
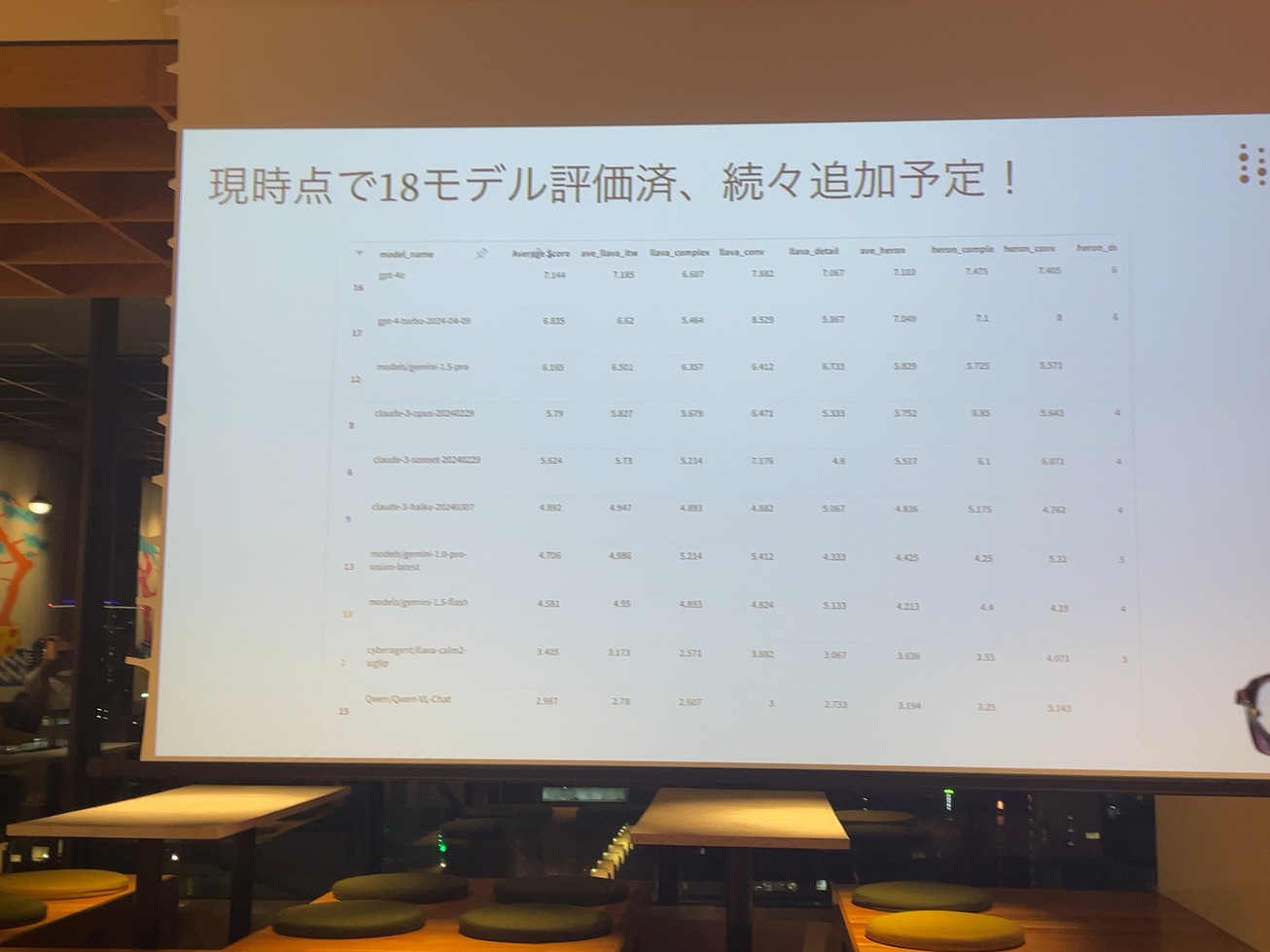 現在こちら、全部で18までビジョンランゲージモデルを収録しておりまして続々追加していく予定です。これまでのモデル評価に比べて、今までのテキストだけではなくて画像も含めたタスクについてのモデルの、性能評価をしています。
現在こちら、全部で18までビジョンランゲージモデルを収録しておりまして続々追加していく予定です。これまでのモデル評価に比べて、今までのテキストだけではなくて画像も含めたタスクについてのモデルの、性能評価をしています。
 内容については次、山口さんの方からご紹介あるんじゃないかなと思うんですけれども、いわゆるビジュアルクエスチョンアンサー、画像も交えてのQXの回答品質を評価していくということをしております。
内容については次、山口さんの方からご紹介あるんじゃないかなと思うんですけれども、いわゆるビジュアルクエスチョンアンサー、画像も交えてのQXの回答品質を評価していくということをしております。
現状としてはこんな勢力図になっておりまして、gpt4およびその継続、Gpt4oがリードをしているという状況で、それをその他の商用APIが追っかけて感じになっています。OpenAIのモデルはちょっとまだまだ、そういうAPIと比べてちょっと差がまだまだついている状況ではあるんですけれども、ちょうど一年前、弊社のLLMのリーダーボードを出した時の二年の状況でしたのでこれから一年経ったらもう全然変わってくるんじゃないかなと期待しております。
 これはよくあるのは、とあるモデルAとBがあって、パフォーマンスが違ってそれが実際どういう挙動に起因して、何が実際違うの?図だけ見てもわからない。で、実際、中身見てみようってあると思います。ただ、選ばれたCload3、Gemini1.5proと比較してますけれども、このヘローのコンプレックスではCload3が強いけれども、こっちではGeminiが強いなと実際質問どう違うんだと。
これはよくあるのは、とあるモデルAとBがあって、パフォーマンスが違ってそれが実際どういう挙動に起因して、何が実際違うの?図だけ見てもわからない。で、実際、中身見てみようってあると思います。ただ、選ばれたCload3、Gemini1.5proと比較してますけれども、このヘローのコンプレックスではCload3が強いけれども、こっちではGeminiが強いなと実際質問どう違うんだと。
ちょうど去年一年前ぐらい、どんな感じだったかっていうと、ABEJAさんとか先に少し出していた後に、CyberAgentさんとrinnaさん、日本語のLLMを出してちょうど出した直後に、このイベントにご登壇いただいて非常に盛り上がったというこちらですね。そこからたった一年でこのようなところにまで来て非常に進歩が激しいなと。先ほどAlexNetからも12年、そんな話になって一年も短ければ12年も短いなって話ですけれども、これから発展が楽しみでなりません。そして今回のリーダーボード中身の方はチームさんが見るとたくさん乗り込んでるんですけれども、このリーダーボードとしての仕分けではビデオを加わっています。一つ目、レーダーチャートと比較テープルとか連動して動きます。
この下の方を見るとこれとこれ合わせて比べたいっていうので、チェックを入れることができて。例えば今、ClaudeとGeminiになってましたけれども、両方消してよいしょ。 せっかくなんでオープンウェイトのモデル同士を比較してみましょうか? 例えばCyberAgentと。Sakanaは進化的までもあるんですかね?比較すると。
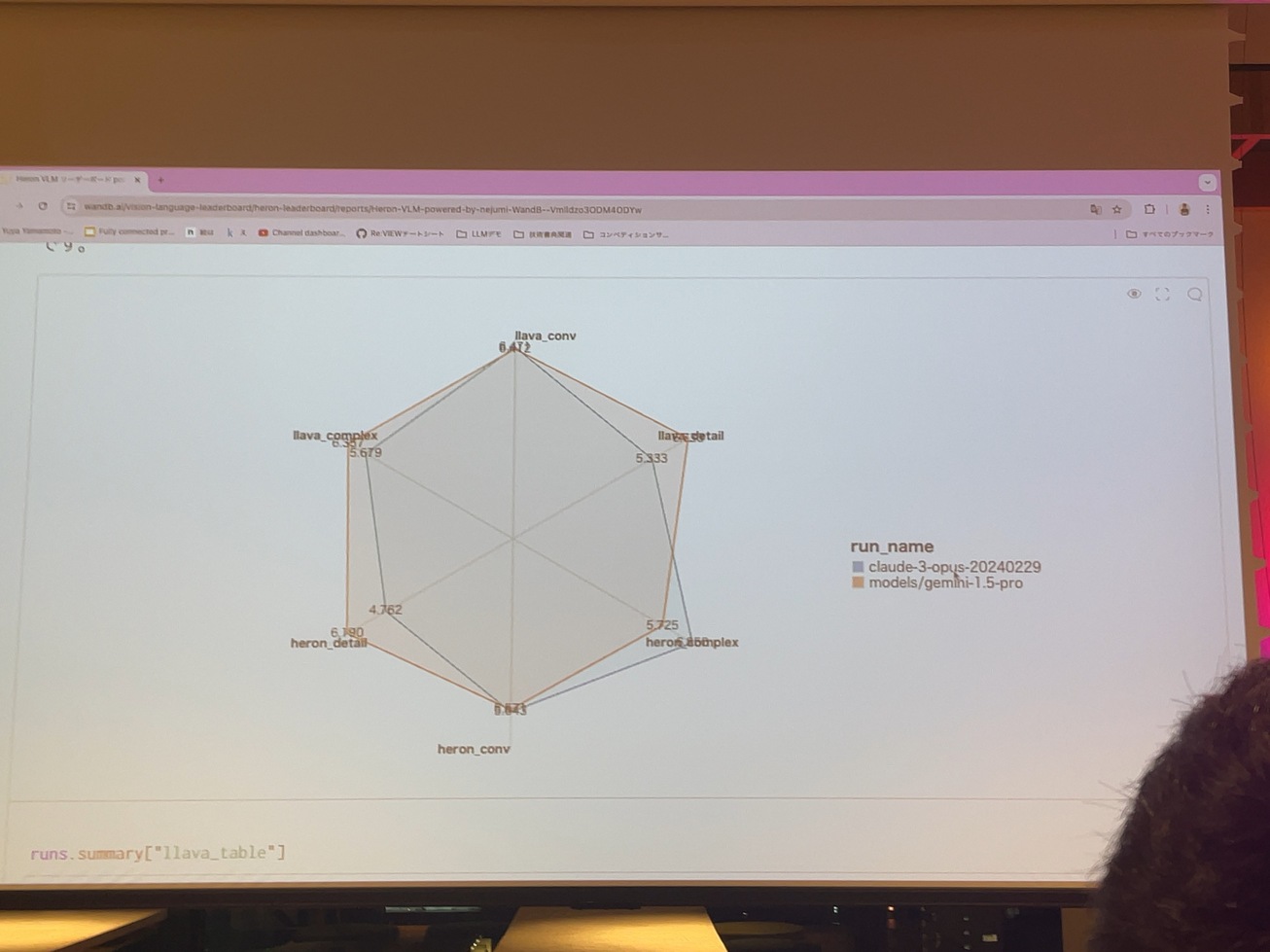 この上のレーダーチャートと、この下の質問応答の深掘りのテーブルが連動します。CyberAgentのモデルとSakana.aiのモデルで、同じ画像に対して同じ質問でそれぞれどう質問回答が異なっていくのか、そしてどう評価されたのか、アジアで行ってることも瞬時に深掘りすることができます。これ見てみるとスライドの方にちょっと解説少し書き加えてあるんですけれども。
この上のレーダーチャートと、この下の質問応答の深掘りのテーブルが連動します。CyberAgentのモデルとSakana.aiのモデルで、同じ画像に対して同じ質問でそれぞれどう質問回答が異なっていくのか、そしてどう評価されたのか、アジアで行ってることも瞬時に深掘りすることができます。これ見てみるとスライドの方にちょっと解説少し書き加えてあるんですけれども。
 もちろんその質問に用いられた画像も含まれた時点で質問を参照できます。で、右の方サイバーモデルは正しくダイヤモンドヘッドって答えていて、スライドの方だとLlama1.5使ってますが、オアフ島にあるダイヤモンドへッド、ハワイ島と間違っていると。ちゃんとジャッジも正しく指摘されていて、その分点数が高いですね。こういうふうに島の名前を間違えたから差があったんだとか。そんなことも瞬時に分かります。このオーバーオールの性能プロファイルの可視化と、個別の入出力、これが随時連動したことで皆様の入退と途中と妨げることがないですこういうので大体よくわかんないデータがよくわからないディレクトリに格納されて一応保存されてるけど、誰も見ないから何の解にもできないっていうのがよくある風景ですけれども、これが劇的に変わっていきます
もちろんその質問に用いられた画像も含まれた時点で質問を参照できます。で、右の方サイバーモデルは正しくダイヤモンドヘッドって答えていて、スライドの方だとLlama1.5使ってますが、オアフ島にあるダイヤモンドへッド、ハワイ島と間違っていると。ちゃんとジャッジも正しく指摘されていて、その分点数が高いですね。こういうふうに島の名前を間違えたから差があったんだとか。そんなことも瞬時に分かります。このオーバーオールの性能プロファイルの可視化と、個別の入出力、これが随時連動したことで皆様の入退と途中と妨げることがないですこういうので大体よくわかんないデータがよくわからないディレクトリに格納されて一応保存されてるけど、誰も見ないから何の解にもできないっていうのがよくある風景ですけれども、これが劇的に変わっていきます
 その他ほぼほぼチューリングの皆様の作っていただいたHeron-BenchおよびLLaVA-Benchの(In The Wild)Japanese バージョンに立脚してるんですけど、いくつか私たちもネズミリーダーズボード一年間運営してきた中で得た知見をもとに
 変更点を加えていますで一点目は視点の違いだと思うんですけど、スコアです。オリジナルバージョンでは、GPT4との点数の比率、相対スコアにしてまして、今回は絶対スコアにさせていただきまして、ほとんど相関、ケース0.98ぐらいで基本的に対応するので、どちらでもいいんじゃないかということと弊社通常のLLMの方も運営してそちらだとMT-Benchなんですね。基本的には LLMのジャッジは絶対スコアなんで統一感ということで合わせました。でもう一つちょっと工夫したところですけれども、
変更点を加えていますで一点目は視点の違いだと思うんですけど、スコアです。オリジナルバージョンでは、GPT4との点数の比率、相対スコアにしてまして、今回は絶対スコアにさせていただきまして、ほとんど相関、ケース0.98ぐらいで基本的に対応するので、どちらでもいいんじゃないかということと弊社通常のLLMの方も運営してそちらだとMT-Benchなんですね。基本的には LLMのジャッジは絶対スコアなんで統一感ということで合わせました。でもう一つちょっと工夫したところですけれども、
 ジャッジのプロンプトを調整しました。特にその中でも日本語で回答できない問題にペナルティを与えるように指示を追加しています。日本語で答えられなかった点数、ペナルティ、もっと下げてくださいという指示文が加わっています。これ、LLMの海外でも、よく指摘される問題です。意外と回答できてないモデル、日本語は回答できてないモデルも多くて。しかしながら点数が結構高くなっちゃってるんじゃないかと。ちゃんと評価できてるんですか?と。これは弊社のネズミリーダーボードネオの時から指摘されていることです。本日はもうネオを出すローンチ前からこの問題には気付いていて、パーフェクトの対策はできてはいないのですが、一定の対策をすでに盛り込んで最初から出しています。
ジャッジのプロンプトを調整しました。特にその中でも日本語で回答できない問題にペナルティを与えるように指示を追加しています。日本語で答えられなかった点数、ペナルティ、もっと下げてくださいという指示文が加わっています。これ、LLMの海外でも、よく指摘される問題です。意外と回答できてないモデル、日本語は回答できてないモデルも多くて。しかしながら点数が結構高くなっちゃってるんじゃないかと。ちゃんと評価できてるんですか?と。これは弊社のネズミリーダーボードネオの時から指摘されていることです。本日はもうネオを出すローンチ前からこの問題には気付いていて、パーフェクトの対策はできてはいないのですが、一定の対策をすでに盛り込んで最初から出しています。
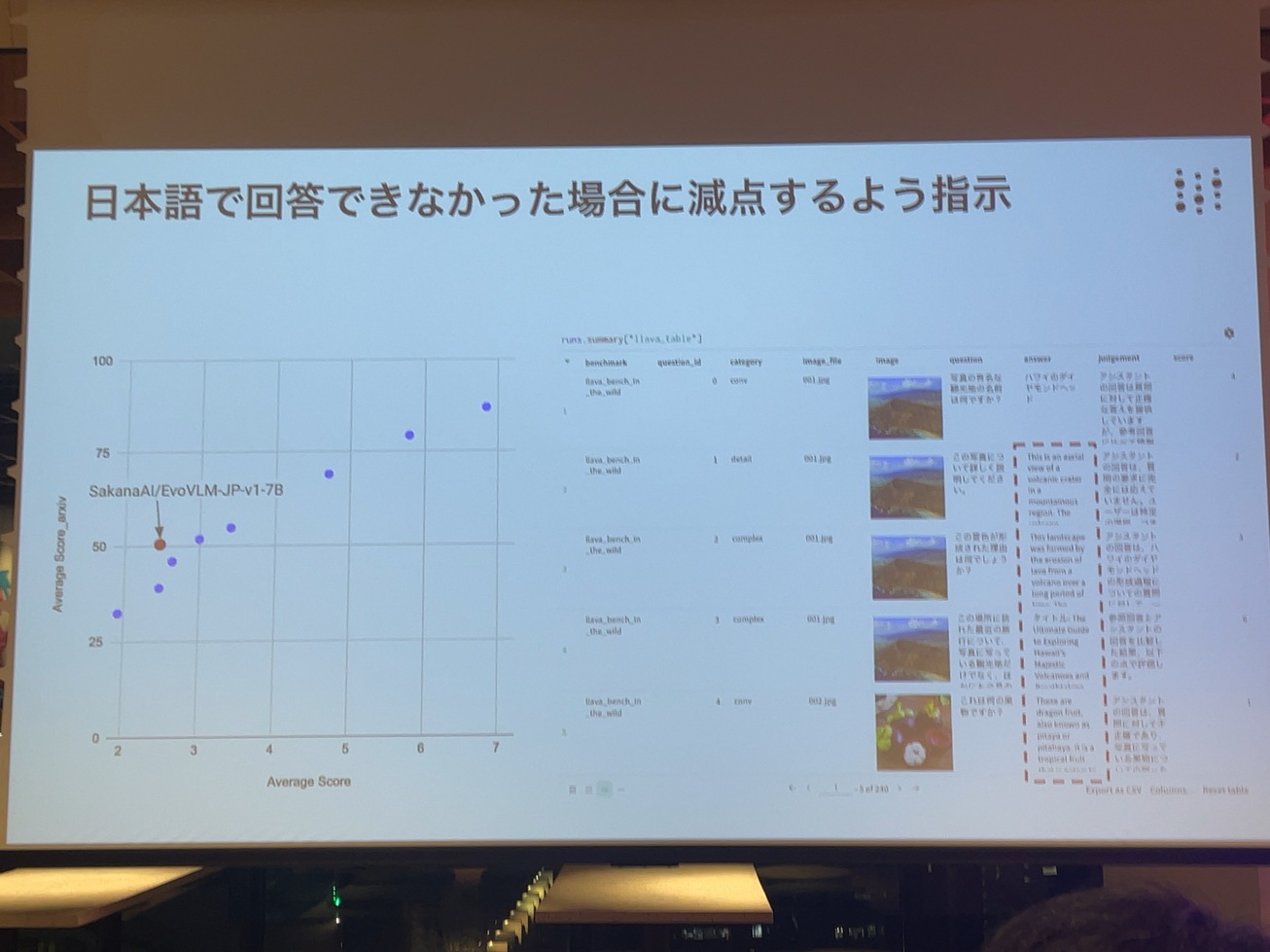 推敲の完璧さはそこまではない。でもちゃんと下がっていますはい。
推敲の完璧さはそこまではない。でもちゃんと下がっていますはい。
 このように、日本語で答えられなかった場合には、点数を差引いてくださいというプロンプトを追加して、実際、事前に実験を合わせて、日本語で全然答えられない当時のモデルもちゃんと、スコアが下がることを確認しています。ただMathですとか、コーディングなどでは、あまり下げなくていいよみたいなことも言っています。ほとんど会社のコードばっかりなので、それで日本語を喋ってなんか点数に付いてもちょっと意味ないですよね。あまり本質的に必要でないコーディングでは、そこは免除します。で限定的ながら一定の効果を確認できています。これも結構頑張ってプロンプトチューニングしたんですけども、割とgpt4は言語の区別、日本語も英語も彼の中ではそんなに区別はついてないので羨ましいことに、ちゃんと点数はいてくれるんです。
この変更点は今回のHeron VLMリーダーボードにおいても認められます。これオリジナルのアーカイブのプレプリントの中でSakana.aiのEvoVLMがかなり上に来てたと思うんですけれども、実際、今回、評価してみると、あまり日本語でしゃべる部分もありますが、ちょっと複雑な内容になってくると、このほとんど英語になってしまったりとかして、これ、出た直後にブログ記事とかでみんな試して日本語喋ってませんだって思ってたと思うんですけども、もらってる評価すると、日本語しゃべるよりも、どちらかというと英語の方が多いですねで私たちは、今回日本語しゃべれなかったら、ちゃんと点数減点するというのを入れて、こう一つですので、これだけこの相関のプロットカード、外れていて、改訂を認められ、これこの解では日本語力、違いに実際、ジャッジも、日本語しゃべれてないから、点数を下げましたよということ、明確に言っています。回答が英語であるというのも問題です。英語ぐらいだったら別にいいかもしれないんですけれども、言語なんでもいいっていうこと、ちょっと大変、収集つかないのでなんでもいいってわけではない。
今回はローカルな言語、日本語でのタスクの性能を図りたいというのが趣旨ですのでこんな変更を加えております。
で今後の展開です。まず一つ、今後の展開もあるんですけど、一つはコンスタントに行っていくと、こうしたリーダーボード、モデルの評価。多くの開発者の方自身も、自身で行われることですよ。だいたいご自身の開発者ものとコンパラブルな5個ぐらい評価してる論文に掲載して先行経験と比べて提案しとかないですと。でもその後、継続的に、行わないですね。ちょっと私たちは継続的に。
OCRみたいなTextVQAとか表を読めるかみたいなChartQAとか、よく問題は、日本語のデータセット、あんまり整理されてなくて。何かもしあったら教えてください。私が無知なのでこれあるよって感じでね。なかなか日本語と比べ、単に翻訳すればいいいうとのではなくて、文章が画像の中に入っちゃってるんで、その投資がないところ、汗かいて作るしかないかも知れませんというところで、私の方からは以上です。ネズミリーダーボードに加えて、Heron VLMリーダーボードの方、皆様、よろしくお願い致します。
このように、日本語で答えられなかった場合には、点数を差引いてくださいというプロンプトを追加して、実際、事前に実験を合わせて、日本語で全然答えられない当時のモデルもちゃんと、スコアが下がることを確認しています。ただMathですとか、コーディングなどでは、あまり下げなくていいよみたいなことも言っています。ほとんど会社のコードばっかりなので、それで日本語を喋ってなんか点数に付いてもちょっと意味ないですよね。あまり本質的に必要でないコーディングでは、そこは免除します。で限定的ながら一定の効果を確認できています。これも結構頑張ってプロンプトチューニングしたんですけども、割とgpt4は言語の区別、日本語も英語も彼の中ではそんなに区別はついてないので羨ましいことに、ちゃんと点数はいてくれるんです。
この変更点は今回のHeron VLMリーダーボードにおいても認められます。これオリジナルのアーカイブのプレプリントの中でSakana.aiのEvoVLMがかなり上に来てたと思うんですけれども、実際、今回、評価してみると、あまり日本語でしゃべる部分もありますが、ちょっと複雑な内容になってくると、このほとんど英語になってしまったりとかして、これ、出た直後にブログ記事とかでみんな試して日本語喋ってませんだって思ってたと思うんですけども、もらってる評価すると、日本語しゃべるよりも、どちらかというと英語の方が多いですねで私たちは、今回日本語しゃべれなかったら、ちゃんと点数減点するというのを入れて、こう一つですので、これだけこの相関のプロットカード、外れていて、改訂を認められ、これこの解では日本語力、違いに実際、ジャッジも、日本語しゃべれてないから、点数を下げましたよということ、明確に言っています。回答が英語であるというのも問題です。英語ぐらいだったら別にいいかもしれないんですけれども、言語なんでもいいっていうこと、ちょっと大変、収集つかないのでなんでもいいってわけではない。
今回はローカルな言語、日本語でのタスクの性能を図りたいというのが趣旨ですのでこんな変更を加えております。
で今後の展開です。まず一つ、今後の展開もあるんですけど、一つはコンスタントに行っていくと、こうしたリーダーボード、モデルの評価。多くの開発者の方自身も、自身で行われることですよ。だいたいご自身の開発者ものとコンパラブルな5個ぐらい評価してる論文に掲載して先行経験と比べて提案しとかないですと。でもその後、継続的に、行わないですね。ちょっと私たちは継続的に。
OCRみたいなTextVQAとか表を読めるかみたいなChartQAとか、よく問題は、日本語のデータセット、あんまり整理されてなくて。何かもしあったら教えてください。私が無知なのでこれあるよって感じでね。なかなか日本語と比べ、単に翻訳すればいいいうとのではなくて、文章が画像の中に入っちゃってるんで、その投資がないところ、汗かいて作るしかないかも知れませんというところで、私の方からは以上です。ネズミリーダーボードに加えて、Heron VLMリーダーボードの方、皆様、よろしくお願い致します。
 且つ網羅的に行うことでこの業界に貢献していければなと思っておりますのでなかなかそういう組織っていうか、オーガニゼーションないと思うので地道にやっていきたいと思っております。それから、評価系も今後ちょっとまだまだ悩んでるんですけど、現状ではビジュアルクエスチョンアンサー(VQA)が2種類ですが、このビジネスビザマーケティングモデルで先行してる商用のモデルを見ると、様々な評価がなされていることがわかります。ちょっと紙面の都合でクロードのが乗っけてないですけど、クロードこんな感じ、こちらどうぞ世の中的にはどんなことが行われてるかっていうのは、見て取れるわけですが、代表的なところですとMMMUの上位が決まったと思いますけれども、リーズニングみたいなところ
且つ網羅的に行うことでこの業界に貢献していければなと思っておりますのでなかなかそういう組織っていうか、オーガニゼーションないと思うので地道にやっていきたいと思っております。それから、評価系も今後ちょっとまだまだ悩んでるんですけど、現状ではビジュアルクエスチョンアンサー(VQA)が2種類ですが、このビジネスビザマーケティングモデルで先行してる商用のモデルを見ると、様々な評価がなされていることがわかります。ちょっと紙面の都合でクロードのが乗っけてないですけど、クロードこんな感じ、こちらどうぞ世の中的にはどんなことが行われてるかっていうのは、見て取れるわけですが、代表的なところですとMMMUの上位が決まったと思いますけれども、リーズニングみたいなところ
「日本語Vision-Languageモデルの学習と評価ベンチマークの構築」 山口 祐さん
みなさん、こんばんは。
チューリング株式会社の山口と申します。今日はよろしくお願いいたします。今山本さんの方からHeron VLMリーダーボードをご紹介をいただいたんですけれども、私の方からはその裏側、その中身がどういうふうに評価しているかというところと、我々の作っているところ、自動運転にどういうふうにつながっているかといったところを幅広くご紹介できたらなと考えております。
 まず私の方の自己紹介ですけれども、朱里株式会社でAI開発のディレクターをしている山口です。
まず私の方の自己紹介ですけれども、朱里株式会社でAI開発のディレクターをしている山口です。
もともとキャリアとしてはつくばにある三総研という研究所とか、アメリカのNISTとかで研究していたんですけれども、このAIブームの中、囲碁とか将棋とかのゲームAIを作ると面白いんじゃないかと思って。それを始めたというのが、この世界に入ったきっかけ。
チューリングに入る前は上場企業のAI開発の執行役員をしていたりしていたんですけれども、2022年にチューリングの創業メンバーとして加わって、それ以来、自動運転開発の責任者として、いろいろとやっていくというような立場になっております。
 チューリング株式会社という会社についても、ちょっと簡単にご紹介していこうと思います。
チューリング株式会社という会社についても、ちょっと簡単にご紹介していこうと思います。
チューリングという会社は、AIとカメラのみでハンドルがない車を作るということを目指しているスタートアップになっております。
AIとソフトウェアという、新しい切り口で車を作ろうというところを目指している会社になっていて。ソフトウェアエンジニアが中心になって回転している企業になっていて、創業が2021年の8月ということで、もうそろそろ三年になるという会社ですけれども、正社員は今40人を超えて、45人ぐらいになっているというところです。
2024年の4月には、累計で45億円程度の資金調達を行っているというところで、シードブランドのスタートアップとしては国内でもかなり規模が大きい会社になっております。
我々の一番の特徴として、自動運転の中でも一番難しいとされている完全自動運転、これはまだ人類誰もできていないような技術なんですけれども、これを目指すための技術開発をしていて、AI開発だけじゃなくて、車だったり半導体だったり。そういったハードウェア面からも含めて、いろいろ開発も進めているという感じです。
 今日お話しする内容は、大きく分けて三つあります。先ほどご紹介いただいたビジョンランゲージモデル、LLMに視覚の機能をつけたといったところですけど、これを中心にお話していこうと思いますけれども、そもそもそういったビジョンアンドランゲージ、言い換えるとマルチモーダルモデルってどういうものかっていったところでお話します。評価する学習した後に評価するために仕様みたいなところもお話しします。
今日お話しする内容は、大きく分けて三つあります。先ほどご紹介いただいたビジョンランゲージモデル、LLMに視覚の機能をつけたといったところですけど、これを中心にお話していこうと思いますけれども、そもそもそういったビジョンアンドランゲージ、言い換えるとマルチモーダルモデルってどういうものかっていったところでお話します。評価する学習した後に評価するために仕様みたいなところもお話しします。
最後に、ミートアップのテーマであるデプロイ、これを車に乗せる時どうすればいいんだっけ?みたいな悩みみたいなところもお話できたらと思います。
まず、マルチモーダルモデルというところで。
 導入のところなんですけど、まずこういった写真ですね。道路工事してるという。道路があった時に、この状況で左折したいなと思った時に、今皆さんのドライバーだと思ってちょっと考えてもらいたいんですけども。
導入のところなんですけど、まずこういった写真ですね。道路工事してるという。道路があった時に、この状況で左折したいなと思った時に、今皆さんのドライバーだと思ってちょっと考えてもらいたいんですけども。
どこを見ます?というところですね。
いろんな見るべきポイントがあるかなと思うんですけども、実は人間いろんなところを無意識的に見ています。まず、この手前に誘導員がいるので、この誘導員の人が止まれと言っているのか、行けと言っているのか。誘導員の人が向こうを向いているから、どっちの意思かもわかる。あと信号機があって誘導員ってどっちを優先するのか?実は奥にも小さいですが、誘導員がもう一人いて、この人と指示がちゃんと連携取れているのか。看板が日本語で書いてありますとか、カラーコーンが置いてあるとか、そういったところを意味を理解しています。
人間はこういう文脈を無意識的に理解しているということですね。
高度な自動運転には視覚の情報と言語的な情報、言語的な理解が高度に融合していないと難しいイレギュラーな状況の判断が自動的にできない。昨年の末ぐらいから、第3世代と呼ばれるような、LLM自然言語とカメラ画像だけを使って運転をしようとするモデルとデータセンターを用意するということがあります。国際会議や論文の傾向を見てると、自動運転のところがLLMを使ってどうするか、これまでできなかったような難しいシチュエーションをどう解決するかといったところに軸を置いているようです。
 自動運転の業界でも新しい波が来ていて、第3世代の自動運転タスクが非常に注目されています。深層学習ベースの自動運転の学習データは、2012年頃から整備されていて、2012年頃からCNNをターゲットにしたものがあったり、2019年頃からトランスフォーマーをターゲットにした複雑なデータセットが用意されていたりしています。
自動運転の業界でも新しい波が来ていて、第3世代の自動運転タスクが非常に注目されています。深層学習ベースの自動運転の学習データは、2012年頃から整備されていて、2012年頃からCNNをターゲットにしたものがあったり、2019年頃からトランスフォーマーをターゲットにした複雑なデータセットが用意されていたりしています。
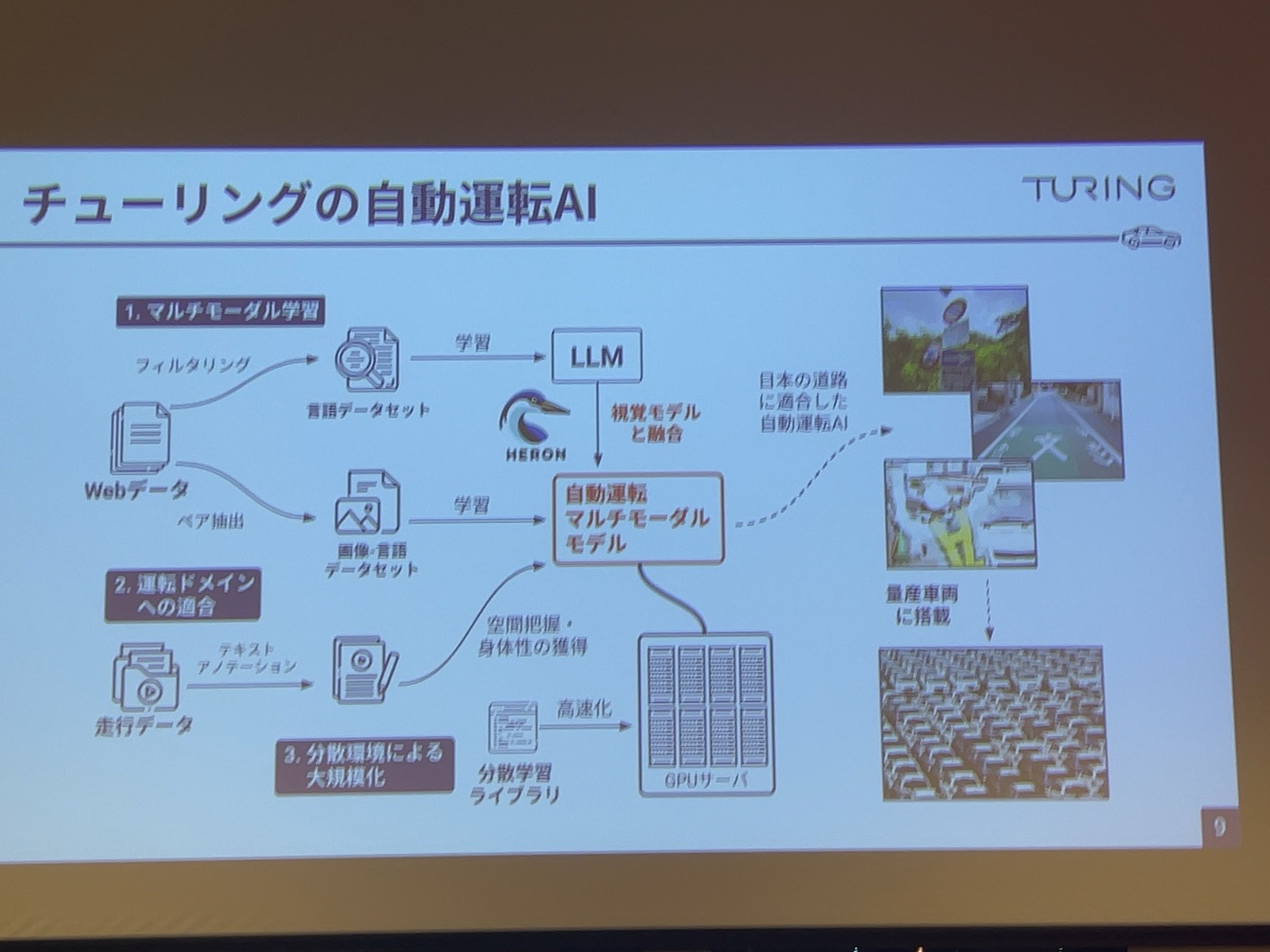 チューリングは、創業当初からマルチモーダルAIを使うというところで、開発も進めていて、LLMをベースとしたマルチモーダルのAIを作って、運転ドメインを獲得させて大規模に学習することによって、日本の道路に適応した自動運転AIを作って、これを自社生産の車に搭載するといったところを基本的には目指しています。
チューリングは、創業当初からマルチモーダルAIを使うというところで、開発も進めていて、LLMをベースとしたマルチモーダルのAIを作って、運転ドメインを獲得させて大規模に学習することによって、日本の道路に適応した自動運転AIを作って、これを自社生産の車に搭載するといったところを基本的には目指しています。
マルチモーダルAIってどうやって作るんだって話があります。今、マルチモーダルAIは入力と思っていただいて、言語だけじゃなく複数の入力、例えばテキストと画像とか、あるいは映像ビデオとテキストとか、音声とか。いろんな入力の形式がありますが、複数入れたり、複数出したりできるモデルです。
今、基本的にはLLMベースとなる学習済みのテキストを入れてテキストを出すLLMがあって、それをうまく使って、ビデオとかイメージを解釈する別のモデルをくっつけることによって、新しいモダルを獲得させる手法が一般的になっています。
 CLIP以降、その他のモーダルと言語、テキスト情報と結びつけるのが簡単になりつつあるので、その手法を使って、既存のLLMは非常に性能が高いというのは、皆さんご存知の通りだと思いますので、それによって学習コストが非常に抑えられるというところがあります。
CLIP以降、その他のモーダルと言語、テキスト情報と結びつけるのが簡単になりつつあるので、その手法を使って、既存のLLMは非常に性能が高いというのは、皆さんご存知の通りだと思いますので、それによって学習コストが非常に抑えられるというところがあります。
ええ、最近ですとそのgpt4とかGemini1.5Proとかですね。非常に。 商用のモデルですね。非常に民生の上がっているというところもありますし、この右側の図はですね。何かというと、2023年以降に出た主要なマルチモダルの一覧みたいなところで、これも2024年の2月までしかビジュアルは載ってないんですけども、MetaとかMicrosoftとか、いろんな企業ですね。次から次へと大規模モデルをマルチモーダルモデルも出していた形になっています。
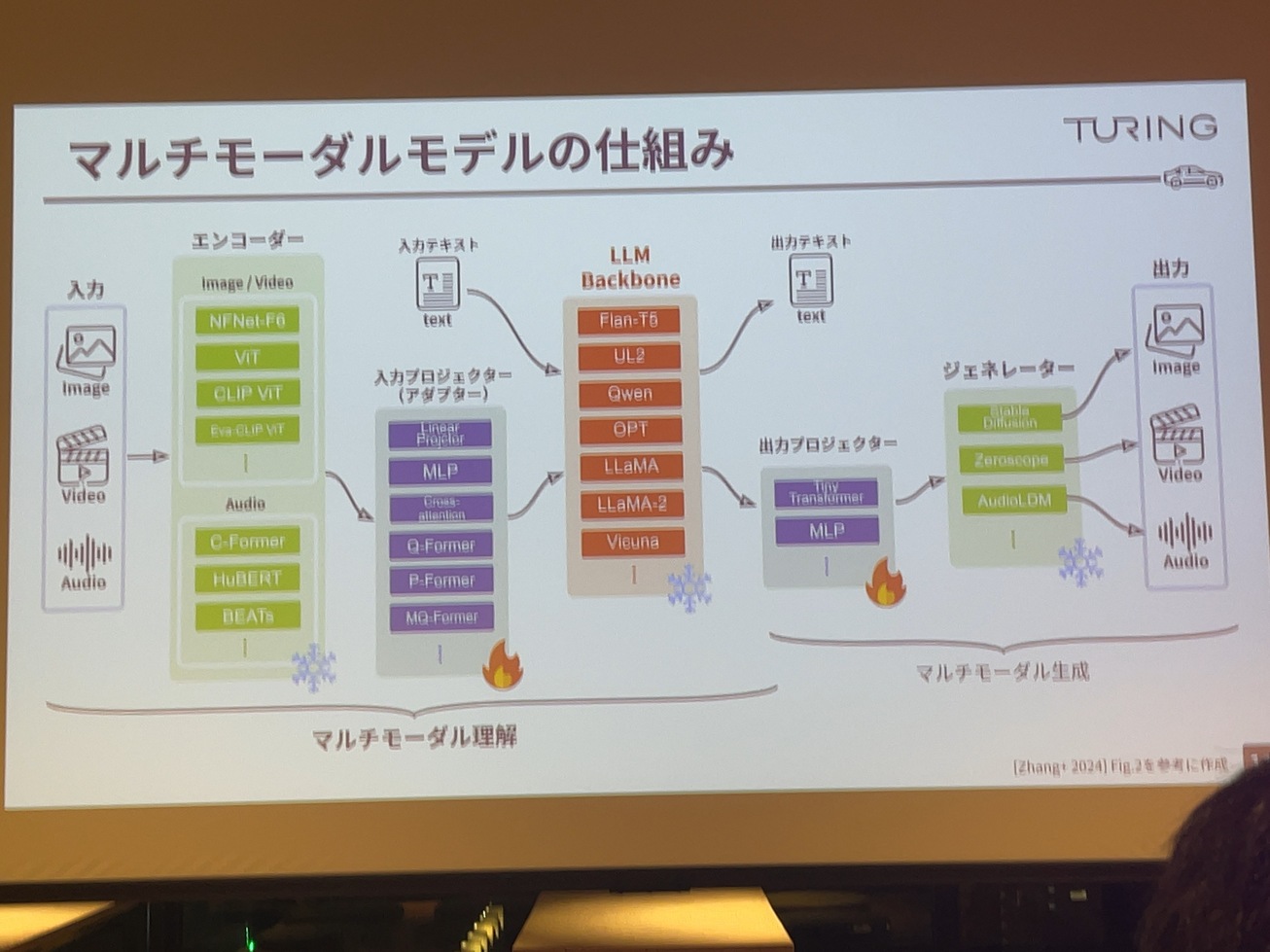 マルチモータルモデルの仕組みなんですけれども、これが非常にざっくりとした説明の図なんですけれども、左からこう入力があって、一番右が出力といった形。
マルチモータルモデルの仕組みなんですけれども、これが非常にざっくりとした説明の図なんですけれども、左からこう入力があって、一番右が出力といった形。
通常マルチモーダルモデルだと画像とかを入れてテキストを出すみたいなところで、マルチモーダル理解と言われています。
入力のものですね。エンコーダと呼ばれるような、clipとかピットとかエヴァクリックとか、イメージの変更だみたいなこと言うか。常にこれも学習済みのものがあるとしてですね。それとは別に、真ん中のLLMバックボーンですね。これがすでに学習済みのエルエルで、例えばLlama3とかLlama2とかQwenとか、すでにあるアーキテクチャの得れるものがあって、重要なのがその間にある入力プロジェクトアダプタと呼ばれる。
ここが既存のそれぞれ学習済みのエンコーダ。画像モデルとLLMにつなぐためのつなぎみたいな部分で、ここの部分を中心的に学習することによって、画像エンコーダーの方から出てきた任意のこの7億ベクトルみたいなところをうまくエネルギーの方が解釈できるような表現に変換してやっていなくて、既存のLLMもそのまま使って、テキスト情報を見たい形で言語組み込んで、それでLLMの性能そのまま引き出すというのが基本的なマルチモーダルの仕組み。
こういったマルチモーダルも選択肢が多くて、画像エンコーダーだけでもたくさんありますし、アダプターもたくさんありますし、LLMもたくさんで、学習方法とかデータセットも無数にあって、どういうふうに組み合わせたりとかすごい大変だと。
Heronはできるようになっていて、これは国内でも先駆けてマルチモーダルの所を展開できたのかなと思ったのと。
 チューリングの場合ですね。これ去年の7月ぐらいにリリースしたんですけども、こういったところ。色々組み替えて学習するためのライブラリみたいにして、これは学習ライブラリHeronという名前でヘロンは英語の青鷺です。そういったところで学習ライブラリをオープンソースとして実は公開しています。さっき言ったように、画像エンコーダとかアダプターとか現行モデルこれを非常に簡単にそのconfigファイルを書き換えることがあって、全部のモデルに組み替えて、あるいはデータセットとか学習を分散学習みたいなところですね。
チューリングの場合ですね。これ去年の7月ぐらいにリリースしたんですけども、こういったところ。色々組み替えて学習するためのライブラリみたいにして、これは学習ライブラリHeronという名前でヘロンは英語の青鷺です。そういったところで学習ライブラリをオープンソースとして実は公開しています。さっき言ったように、画像エンコーダとかアダプターとか現行モデルこれを非常に簡単にそのconfigファイルを書き換えることがあって、全部のモデルに組み替えて、あるいはデータセットとか学習を分散学習みたいなところですね。
 具体的に我々が学習したモデルで、さっきの画像を推論してみるとですね、こういった形になっていて、この状況ではどのような点に気をつけるべきですか?みたいなところ。聞くと。こういうふうにこの画像では道路工事中の作業員が片側に立っています。あとカラーコーンもありますし特に別に交通自動運転用にチューニングしてるわけじゃないですけど、ちゃんと交通規則を遵守しなければならない。
具体的に我々が学習したモデルで、さっきの画像を推論してみるとですね、こういった形になっていて、この状況ではどのような点に気をつけるべきですか?みたいなところ。聞くと。こういうふうにこの画像では道路工事中の作業員が片側に立っています。あとカラーコーンもありますし特に別に交通自動運転用にチューニングしてるわけじゃないですけど、ちゃんと交通規則を遵守しなければならない。
このあたりは元のLLMがあって、このあたりが性能がすごく上がって、日本語能力の高いものを使っているので画像を入れて言語的に理解するということができているで。最終的にはコーンカラーコーンを迂回したりだとか、一時停止したりするといったことの具体的なアクションで動かしているということですね。
こういうふうにテキストが出てきますというところなんですけども、このテキストどのぐらいあっていますか?みたいな話、実は所々間違っていて、よく見ると黄色いコーンと書いていたりします。カラーコーンは青いコーン。こういうふうにですね。実はもっともらしく書いてるけど、実は間違ってるんですね。この辺の能力がどうやって評価したらいいのかなっていうところで、今日のメインテーマであるその日本語のビジョンアンドランゲージのモデルの強化ベンチャー、そのHeron-Benchをご紹介したいと思います。
これだと単純な質問なんですけれども、昨年出た。VQA。これもVisual Question and Answeringというものがあるんですけど、これがgptをうまく使って、リッチな回答をさせて。それをgpt4自身と比較することによって、定量的に評価できるよっていうところがあって。今回、我々が作ったベンチマークもこれを参考にして。これも日本語の文化研究したので出るという。
visual languageのその評価ベンチマークって結構いろいろあるというところですけども、基本的にはそのVisual Question and Answeringというのは、割と主流であります。これは画像を受けて、この画像に対して質問する。この人のひげは何できてますか?とかピザは何カットされてますか、何ピースにカットされてますか?みたいな質問もして、これは正確に答えるかみたいなところを書いてます。

 実際にそのHeron-Benchというものですね。これは言語と視覚、言論評価もある。評価ベンチマークなんですけれども、その日本語の能力、日本語のLLMみたいなところを評価するベースなんかたくさんあるんですけども、日本語のVisual & Languageに対する評価するベンチマークってほとんどなかったので、自分たちで作りましょうよっていうことで作ったんだけど。
実際にそのHeron-Benchというものですね。これは言語と視覚、言論評価もある。評価ベンチマークなんですけれども、その日本語の能力、日本語のLLMみたいなところを評価するベースなんかたくさんあるんですけども、日本語のVisual & Languageに対する評価するベンチマークってほとんどなかったので、自分たちで作りましょうよっていうことで作ったんだけど。
 ちょうどですね、今日からやってるCVPRですね。コンピュータービジョンのトップカンファレンスです。があるんですけども、そこのワークショップの方に採択されていて、ちょうどこれ、今朝発表してきました。CVPRでやったんですけど、写真。
ちょうどですね、今日からやってるCVPRですね。コンピュータービジョンのトップカンファレンスです。があるんですけども、そこのワークショップの方に採択されていて、ちょうどこれ、今朝発表してきました。CVPRでやったんですけど、写真。
 質問自体はいろいろ作っていて、サブカテゴリーでいろいろ複数あるんですけど、全体の質問が102個、作っているっていう感じです。
質問自体はいろいろ作っていて、サブカテゴリーでいろいろ複数あるんですけど、全体の質問が102個、作っているっていう感じです。
詳細はテックブログの方にありますので、その辺の話を後にでもチェックしていただければと思うんですけれども、実際にじゃあ中身どうなってるかというとご紹介させていただけますでしょうか。 データセットのデータところですね、これがまず日本に由来する。21階の著作権フリーというか、CCが1.0かCC BY 2.0で提示されているような画像を抽出してそれで使っています。
でカテゴリーについてもですねアニメとかカルチャーとか、風景だとか、あと交通とか、その辺で日本の環境特有の画像とか質問を用意していた形に。
 でスコアの算出方法がですね。ちょっと特殊なんですけども、画像を用意して、これをですね。まず人間で詳細にテキスト化する。ここに看板がありますよとか背景に山が見えますよ。そういったところですね。そのコンテキストに対して、gpt4でそのビジュアルじゃない素のGPT4にこういった質問をして、そのコンテキストから回答を出してくださいよっていう。そうすると、gptの回答文がここで出ます。
でスコアの算出方法がですね。ちょっと特殊なんですけども、画像を用意して、これをですね。まず人間で詳細にテキスト化する。ここに看板がありますよとか背景に山が見えますよ。そういったところですね。そのコンテキストに対して、gpt4でそのビジュアルじゃない素のGPT4にこういった質問をして、そのコンテキストから回答を出してくださいよっていう。そうすると、gptの回答文がここで出ます。
最後に自分たちが作ったモデルでこの画像と質問で回答させたものと、解っぽい解答を比較してgpt4自身にあってんですか?と解決させるように。ですので、さっき言ったように、ハワイ島のダイアモンドヘッドみたいなところで微妙な間違いがあったときもgptでこれは分かってる、間違ってるみたいなところを理解していただけます。
で例えばですけども、こちらの画像で。この場所における制限速度は?みたいな質問があって、よく見ると40キロ制限です。 でこれをですね。Gemini1.5Proだときちんと回答できるんですけれども、Cload3だと実はですね。23キロから12キロに減速するみたいなことを書いてあって、多分ちょっと皆さん、見づらいかもしれないですけど、ここにですね。ニセコまで12km、クッチャンまで23kmとあって、ここの看板の文字を誤読してしまっている。 ですので、そのあたりもgpt4がきちんと指摘してくれるという。なんでかなり正確なスコアと言える。 でそれぞれのスコアですね。これもやっぱりモデルごとに傾向が出ていて、Heron-BenchとそれからLLaVa-Benchですね。昨年提案されたもの、日本語訳したっていうデータテストがあるんですけども、それと総合的に比較するみたいなところを、我々の方でいろいろモデルの比較を行って、基本的にやっぱりクローズドモデルですね。GPT4とかCload3とかが高いという話もありますし。
やっぱり英語圏で作られているデータセットに比べて、日本語の能力っていうところを見ると、結構差がある。10ポイントぐらいやっぱりクローズモデルもオープンモデル下がってくるということで、やっぱりGPT4とかすごい日本語力が高いというふうに皆さん思ってるんだけども、やっぱりその日本の文化理解とか日本語能力みたいなところだと、まだまだ英語本家に比べると差があるっていうので、まだ改善の余地があるなというところ。こういったベンチマークの数値からもわかる。
 あとは文化理解みたいの?ちょっと細かい話をするんですけども、これ、結構私、お気に入りの質問なんですけど、この質問の画像で何をしてるかっていう質問です。これ正解は横綱土俵入りって言って、幕内の、その幕内の取り組みの前に、この横綱がテレマティクトなんですけど、ちゃんと見るとやっぱり3人の力士がいるっていうことですね。でも、全部のモデルは実はこれ2人の力士っていうのが大事なんです。
あとは文化理解みたいの?ちょっと細かい話をするんですけども、これ、結構私、お気に入りの質問なんですけど、この質問の画像で何をしてるかっていう質問です。これ正解は横綱土俵入りって言って、幕内の、その幕内の取り組みの前に、この横綱がテレマティクトなんですけど、ちゃんと見るとやっぱり3人の力士がいるっていうことですね。でも、全部のモデルは実はこれ2人の力士っていうのが大事なんです。
これ事前知識としてやっぱり相撲っていうのは、2人の力士が戦うみたいなことがLLM側で持っているので、それに引っ張られて。画像では3人でも引っ張られて2人なんでしょう。悲しいかな?なので、この辺の文化、理解みたいなところと画像が上手く結びつかないみたいなものでも実はこのベンチマークでは見に行ったりします。
 先ほど山本さんにご紹介いただいたように、その今、そのウェイトアドバイスが協力してですね。リーダーポートの方も。
先ほど山本さんにご紹介いただいたように、その今、そのウェイトアドバイスが協力してですね。リーダーポートの方も。
 で今18のビジョンアトランティッションというか比較可能という形になっています。し結構ですね。やっぱり細かいところも見えて、我々自身も非常に結果が見やすくなったなというところで、社内とか評判になっています。
で今18のビジョンアトランティッションというか比較可能という形になっています。し結構ですね。やっぱり細かいところも見えて、我々自身も非常に結果が見やすくなったなというところで、社内とか評判になっています。
 で例えばですけれども、これ今回、リーダーボードを見て思いついたんですけれども、Gemini1.5Proですね。この画像ですね。これ、君たちはどう言ってるかという。映画の一シーンなんですけども。
で例えばですけれども、これ今回、リーダーボードを見て思いついたんですけれども、Gemini1.5Proですね。この画像ですね。これ、君たちはどう言ってるかという。映画の一シーンなんですけども。
この画像に対して質問すると、ちゃんとGemini1.5Proは宮崎駿監督の作品だと考えられます。というところ、何も聞いてないです。答えてくれます。かなり優秀な回答してるなというのが結構。リーダーボードもアンカーリングのところ、見てて気づいたら結構このモデルの性能とか予期してない結果みたいなところも簡単に見えているようでぜひ皆さんも機会があったら、使っていただければ。
 ということでじゃあ最後ここ評価した時に、じゃあそれをどうやってデプロイするかってことを話して終わるかな。で先にちょっと言い訳になるんですけれども、我々の最終的な目的って車に。
ということでじゃあ最後ここ評価した時に、じゃあそれをどうやってデプロイするかってことを話して終わるかな。で先にちょっと言い訳になるんですけれども、我々の最終的な目的って車に。
 生成まあ大規模モデル載せたりする話ですけど、まだ現状は載っていませんと、それはなんで難しいかっていう話をちょっと今からします。
生成まあ大規模モデル載せたりする話ですけど、まだ現状は載っていませんと、それはなんで難しいかっていう話をちょっと今からします。
例えば、車って時速100キロで走っていると、1秒間って27mから28mぐらい。
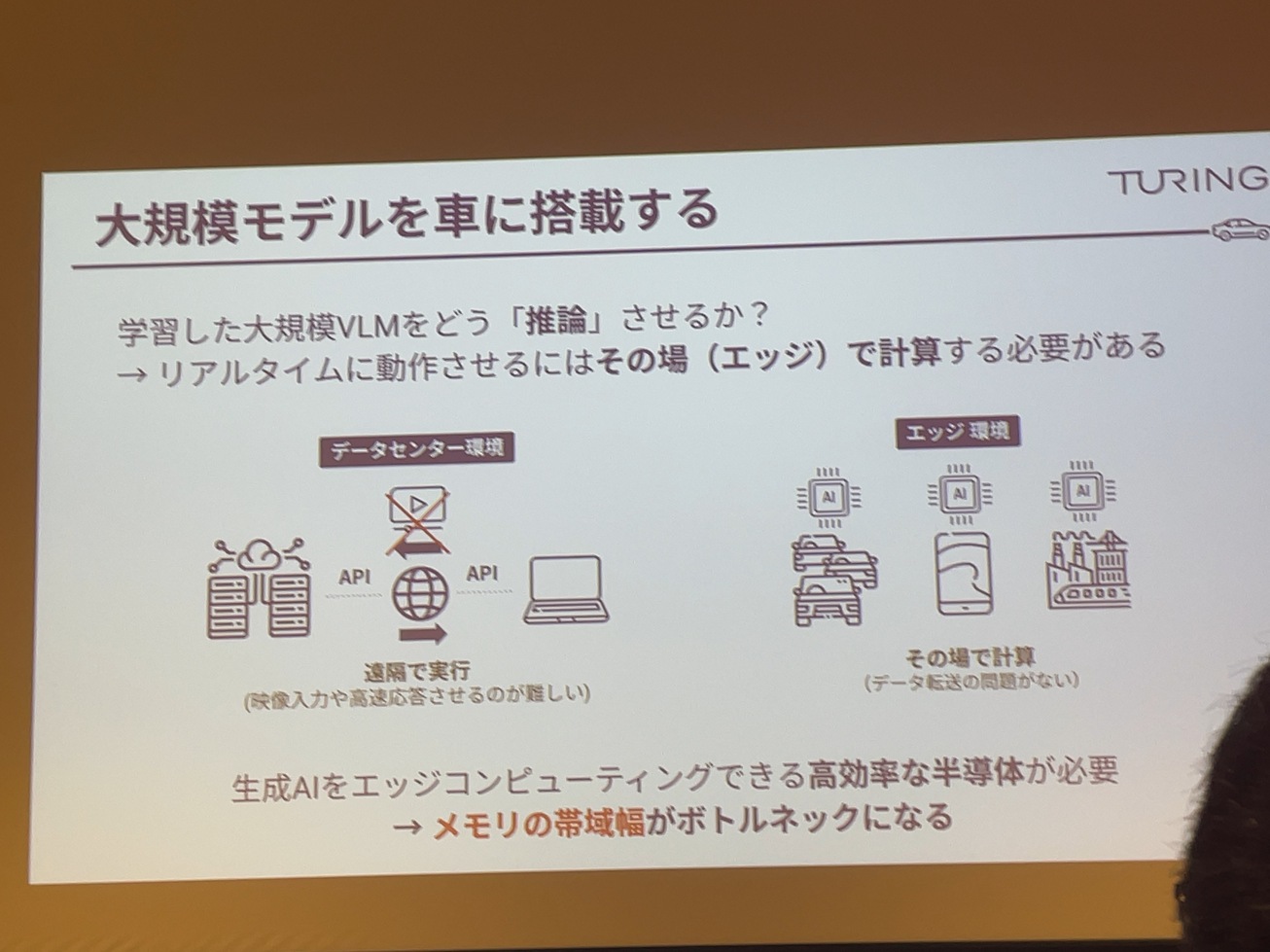 で、大規模モデルを車に乗せるとなると、やっぱりその先ほど前半の公演で、渋井さんの方からお話があったことで、やっぱりその学習環境と推論環境が大きく違うみたいに非常に問題なんですね。で、普通学習をする時って、NVidiaのGPUを使ってデータセンターみたいなことで学習をするといった通りだと思います。ところが、車みたいになっては、いわゆるAPI連携みたいなことはかなり難しいですね。だから普通にAPI投げて待っていくと、車は進んでて、ちょっと気づいたらぶつかってましたということでレイテンシーにシビアです。であと通信環境が必要だということですね。
で、大規模モデルを車に乗せるとなると、やっぱりその先ほど前半の公演で、渋井さんの方からお話があったことで、やっぱりその学習環境と推論環境が大きく違うみたいに非常に問題なんですね。で、普通学習をする時って、NVidiaのGPUを使ってデータセンターみたいなことで学習をするといった通りだと思います。ところが、車みたいになっては、いわゆるAPI連携みたいなことはかなり難しいですね。だから普通にAPI投げて待っていくと、車は進んでて、ちょっと気づいたらぶつかってましたということでレイテンシーにシビアです。であと通信環境が必要だということですね。
通信できないみたいな感じはすごくたくさんあって。山の中とかトンネルの中とか、地下とか、こういった所に完全自動運転みたいなところで想定すると、なかなかインターネット回線で通信が現実的じゃない。つまり、エッジスタンドアローンで避けるような事態です。
そのためにちょっと後ほど紹介説明しますけれども、やっぱりそのメモリの改善みたいなことが一番大きく求められる。このあたりがまだ課題としてある。
 で我々は。結構先に。こういった。言語モデルを環境で動かすための技術開発を進めていて。これは5月献月に出したオープンソースなんですけども、現行モデルをFPGAですね。このボード上で動かす。結構実験的なライブラリを出したいと思います。これはSwanっていう名前でHeronの対になる形で出していますけれども、これは先ほど渋井さんの公演の中でもそのLlama.cppみたいなところのお話があったと思うんですけども、そういった感じでですね。C++で
Llamaアーキテクチャーを全部実装した上でそれをさらにFPGA用にHLFでホイボールでfpgoにを変換してでそれをさらに、FPGAにうまく乗るように頑張って注力して載せたと。
で我々は。結構先に。こういった。言語モデルを環境で動かすための技術開発を進めていて。これは5月献月に出したオープンソースなんですけども、現行モデルをFPGAですね。このボード上で動かす。結構実験的なライブラリを出したいと思います。これはSwanっていう名前でHeronの対になる形で出していますけれども、これは先ほど渋井さんの公演の中でもそのLlama.cppみたいなところのお話があったと思うんですけども、そういった感じでですね。C++で
Llamaアーキテクチャーを全部実装した上でそれをさらにFPGA用にHLFでホイボールでfpgoにを変換してでそれをさらに、FPGAにうまく乗るように頑張って注力して載せたと。
結構なんかしょぼいって言ったわけですけど、エントリー向けのFPGAでちゃんと動いて、これは5万ぐらい通販で買えるようなFPGAなんですけども、ちゃんとその中でもこういったやつね。LLMのオペレーション。
かけたんだけど、そのあとロータリーポジションエムベッド、これはそうですね。もうマライゼーションソフトバンクですね。この辺にあるのっていうことですね。実際にこれFPGAの回路がチップ上にどういうふうにその演算が配置されているかということで、こういった実際にこの半導体でどういう動かすかみたいなところですね。結構真面目に考えて。
これは強い非常になんか簡易的なモデルなんですけれども、今ですね、1ビリオンとか2ビリオンのモデルを動かすための、もっと大規模なFPGAで動かすことをしようとしていて、それが今かなり中心になっています。
なんか結構アンバランスなことが生じていて、特に推論環境でエッジで動かすようになるといわゆるバッチ処理みたいなやつがあんまり行かなくて。
そういった半導体を作っていくみたいなことは、最終的には我々このチップでウエファから起こしてチップに焼き込んで、それを車に載せていくんですけど、そういった時に何が問題になるかっていうと、メモリの対策問題になってるのが先程申し上げたかったFGPUみたいなものって、GPU専用のメモリいわゆるVRみたいな持ってるんですよね。結構ですね。LLMみたいなもので、演算器その計算の部分とメモリーの部分。
マッチサイズ一みたいなやつだと結構高い。それを超えて回さなきゃいけない状況で。そうすると、このメモリーに乗ってる情報から演算機能。
データを転送するところですね。究極的にボトルネックでなんか全然その演算機の性能を活かしきれる形を。
今、現状のNvidiaの車載を検索。多分、普通のLLM 7ビリオンとかモデルを動かすとここのメモリの書いた幅がボトルネックなので、演算器の性能多分1%しか使い切れない。そういった状況です。
 我々のアプローチとしてはここのボトルネックを解消するためにですね。CIM。Compute in Memoryということで、開発していて、メモリのチップ上に演算器を刷ってしまう。一緒にこの載せることによって、ここの同じチェックなんでここの待機はめちゃくちゃこういうところでここの演算とはめちゃくちゃスムーズになるんで、推論はめちゃくちゃ早い。ただ学習とかそういったものはできないし、アーキテクチャが変わると全然動かないんですけど、自分たちのモデルはめちゃくちゃ入る。
我々のアプローチとしてはここのボトルネックを解消するためにですね。CIM。Compute in Memoryということで、開発していて、メモリのチップ上に演算器を刷ってしまう。一緒にこの載せることによって、ここの同じチェックなんでここの待機はめちゃくちゃこういうところでここの演算とはめちゃくちゃスムーズになるんで、推論はめちゃくちゃ早い。ただ学習とかそういったものはできないし、アーキテクチャが変わると全然動かないんですけど、自分たちのモデルはめちゃくちゃ入る。
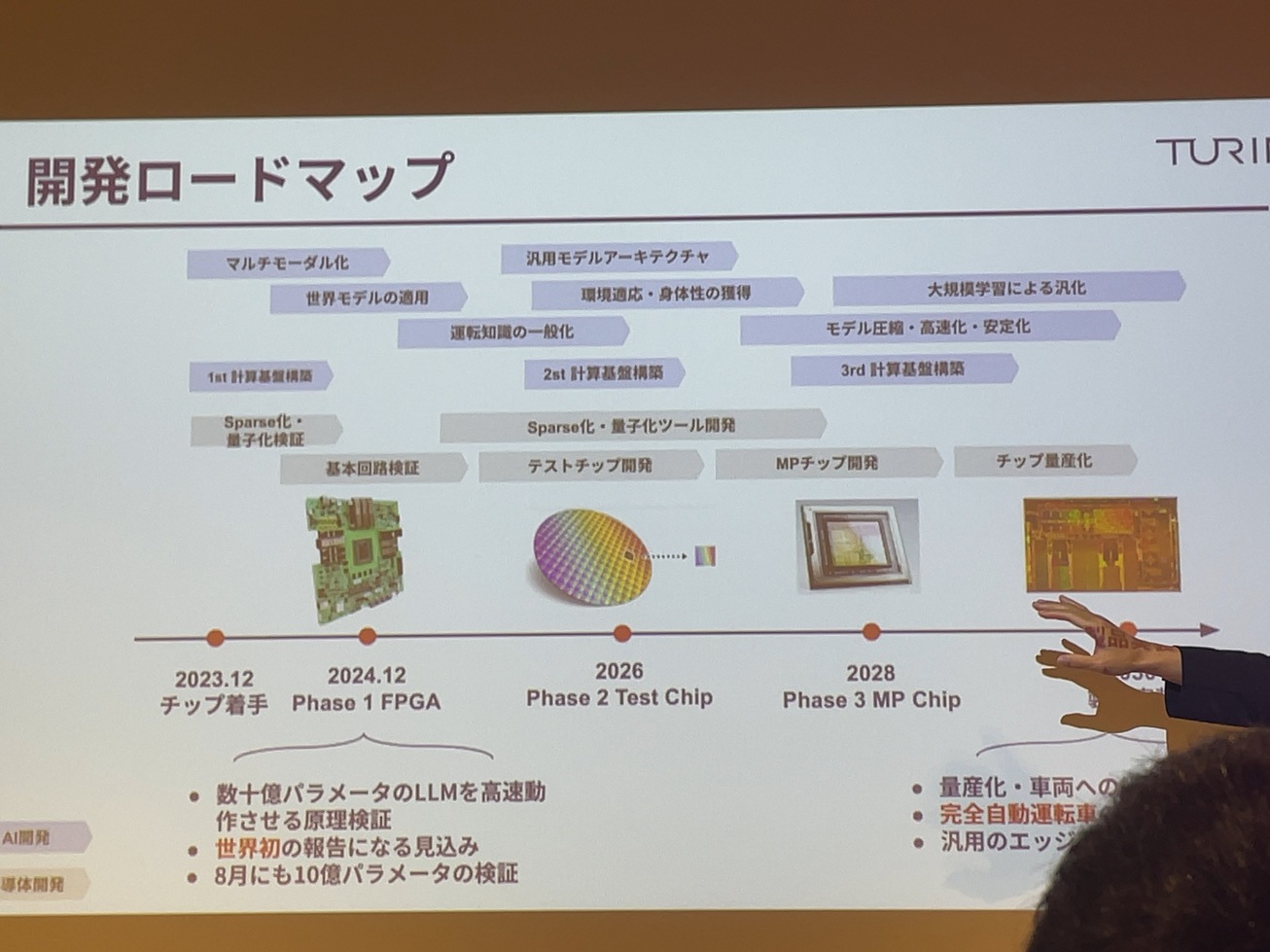 半導体開発はですね。結構遠大な計画になってきて、テストチップを作って量産チップを作って、財布を探してみたいなことをやってたんですね。やっぱり5年とか10年ぐらい前に必要なことで、今はその機構回路の検証をしているかと言ったと思うんですけども、2030年に割とその量産して、自動運転車に乗せるみたいなところを目指してやろうとしています。
一応食品でもですね。今年中にかなり数字をパラメーターも得れるですね。FPGA上でかなり高速に移動させているっていうところは、リリースしようかなと思ってますし、8月夏ごろにもですね。かなり10億パラメーターぐらいのものは動くんじゃないかということができます。まさに注意してから。
半導体開発はですね。結構遠大な計画になってきて、テストチップを作って量産チップを作って、財布を探してみたいなことをやってたんですね。やっぱり5年とか10年ぐらい前に必要なことで、今はその機構回路の検証をしているかと言ったと思うんですけども、2030年に割とその量産して、自動運転車に乗せるみたいなところを目指してやろうとしています。
一応食品でもですね。今年中にかなり数字をパラメーターも得れるですね。FPGA上でかなり高速に移動させているっていうところは、リリースしようかなと思ってますし、8月夏ごろにもですね。かなり10億パラメーターぐらいのものは動くんじゃないかということができます。まさに注意してから。
 Tokyo 30
2025年末までに、カメラとAIだけで東京エリアを30分以上介入なしで走行し続ける自動運転モデルを開発
Tokyo 30
2025年末までに、カメラとAIだけで東京エリアを30分以上介入なしで走行し続ける自動運転モデルを開発
 まとめ
まとめ
質疑応答で道路標識などだけでなく、なぜ運転に関係ない画像があるのかといった質問がありました。山口氏の回答はTuringでは人が運転する時に日本の文化、常識を知っているからこそ運転できるのであり、AIも道路標識だけでなく日本の文化、常識を獲得していることが重要と考えている。ベンチマークにあるような画像は正に自動運転に必要な情報であるということでした。
感想
本イベント前にWandBは知らなかったのですが、MLOpsプラットフォームということで機会があれば使ってみたい。 Heron VLMリーダーボードは最近のVLMの評価サイトということで、VLMを選ぶ際の指標として有用であることが良くわかりました。特に複数のVLMを選んで何が得意で何が不得意なのかを可視化するUIは分かりやすく、瞬時に判断できるのでありがたいと思いました。また、これからも継続して新しいモデルが出てきた時にも対応されるとのことなので楽しみでもあります。 TuringのVLMの評価方法について、一見、自動運転とは関係なさそうな日本の文化的な知識が正しく理解できるかといった評価が実は自動運転で重要であるといった認識は面白いと思った。





